













WhatsApp (принадлежит корпорации Meta, признанной экстремисткой и запрещённой в России) готовит одно из самых заметных изменений за последние годы. Пользователи смогут писать друг другу не только по номеру телефона, но и по настраиваемому имени пользователя.
Для WhatsApp, который годами держался за телефонную книгу как за священную корову, это серьёзное нововведение.
Функция уже начала появляться у части пользователей. Некоторые могут зарезервировать имя прямо сейчас, у других настройка пока недоступна.
WhatsApp обещает, что возможность выбрать юзернейм начнёт распространяться шире уже на этой неделе, а полноценная переписка по именам пользователей заработает позднее в этом году.
Работать всё будет просто: пользователь выбирает себе имя, после чего другие смогут начать с ним чат, зная этот юзернейм. При этом глобального поиска по именам пользователей не будет: чтобы написать человеку, нужно заранее знать его ник.
Для дополнительной конфиденциальности WhatsApp также предложит настроить специальный ключ — по сути пароль, который должен знать человек, пытающийся написать вам по имени пользователя. Это должно защитить от случайных и нежелательных сообщений.
Юзернейм будет необязательным. Номер телефона по-прежнему останется способом связи, а те, кто не хочет выбирать имя пользователя, смогут ничего не менять. Однако если юзернейм настроен, новые собеседники смогут видеть именно его, а не ваш номер телефона.
Зарезервировать имя можно в мобильном приложении WhatsApp: открыть настройки, перейти в раздел аккаунта, выбрать пункт «Имя пользователя» и создать юзернейм. В веб-версии такой возможности пока нет.
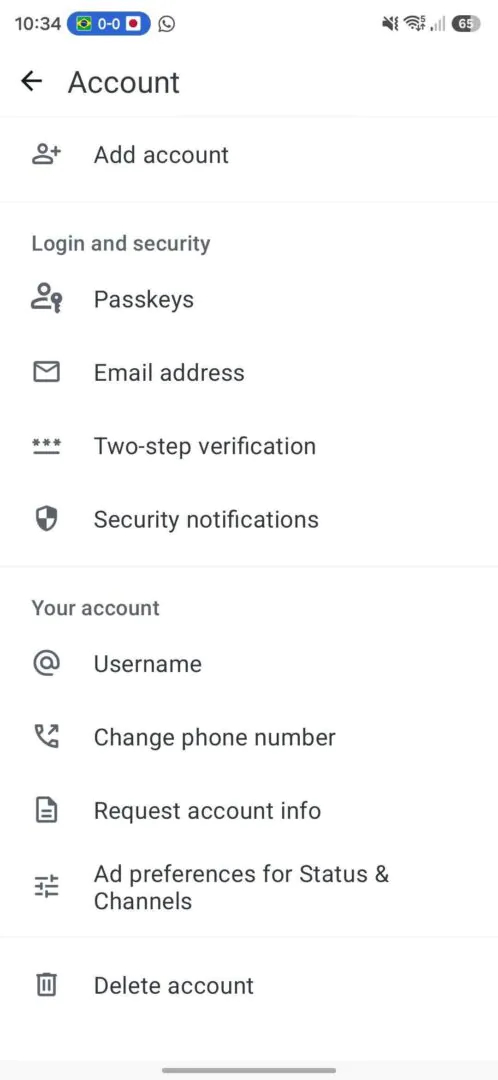
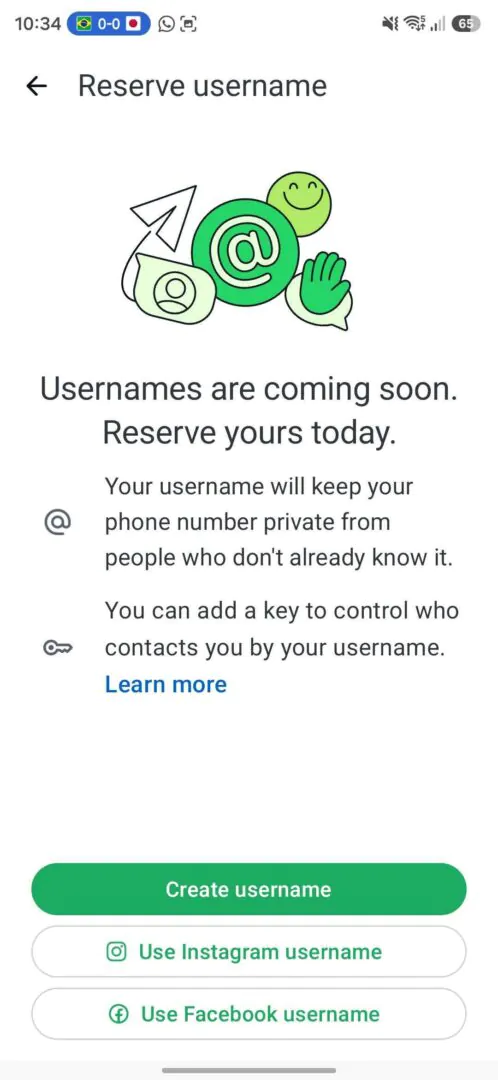
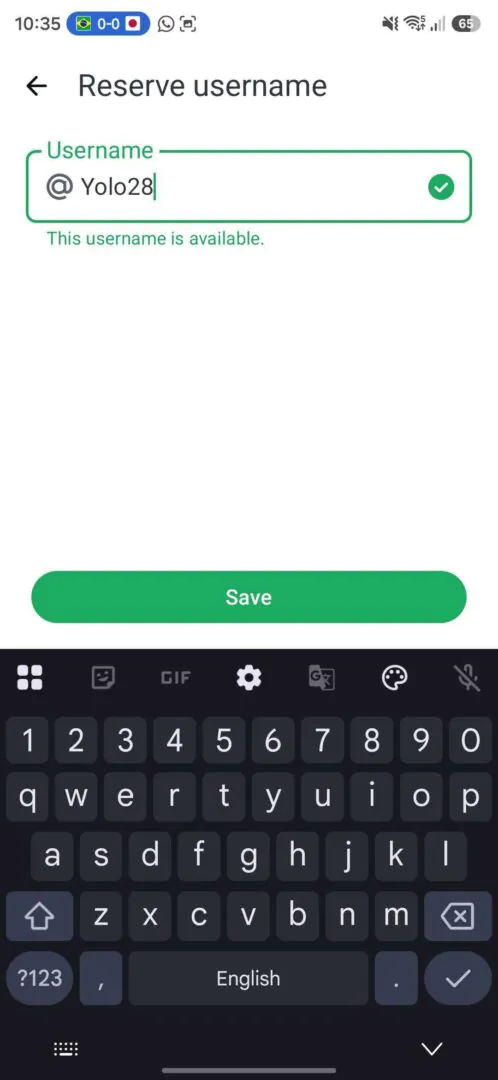
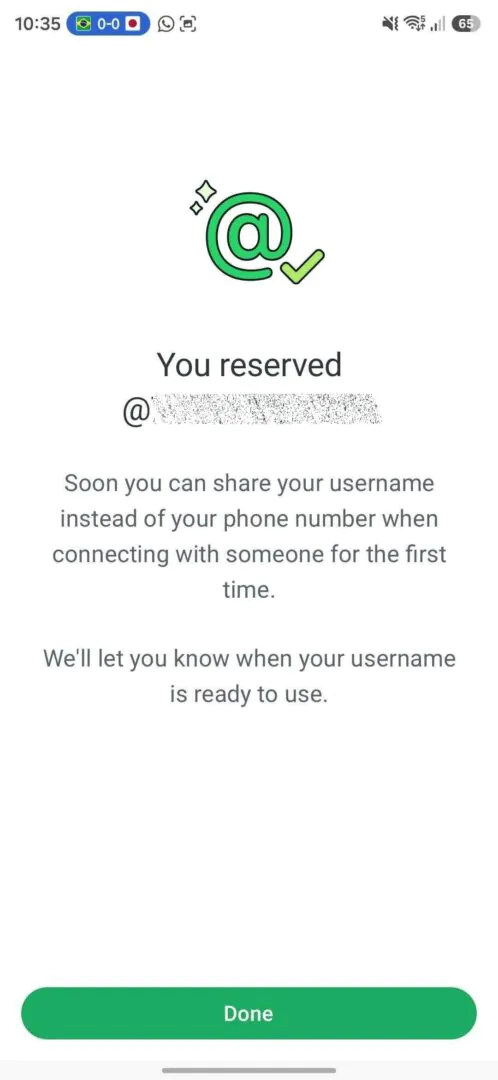
Учитывая аудиторию WhatsApp в миллиарды пользователей, за красивые и короткие ники явно начнется гонка. Так что если вы давно мечтали быть не ivan_928374, а просто ivan, лучше не тянуть.



