














Исследователи Seqrite обнаружили фишинговую кампанию против российских аэрокосмических компаний. Схема получилась уже знакомая: письмо якобы со счётом от реальной авиационной организации. Но внутри не бухгалтерия, а удалённый доступ к компьютеру жертвы через AnyDesk.
Атака начинается с письма, отправленного от имени ВНИИР. Домен похож на настоящий, тема про счёт, оформление с логотипом Минпромторга. Для убедительности всё как надо.
Однако фейковый домен зарегистрировали всего за несколько дней до рассылки, а список получателей скрыт, что намекает на массовую отправку.
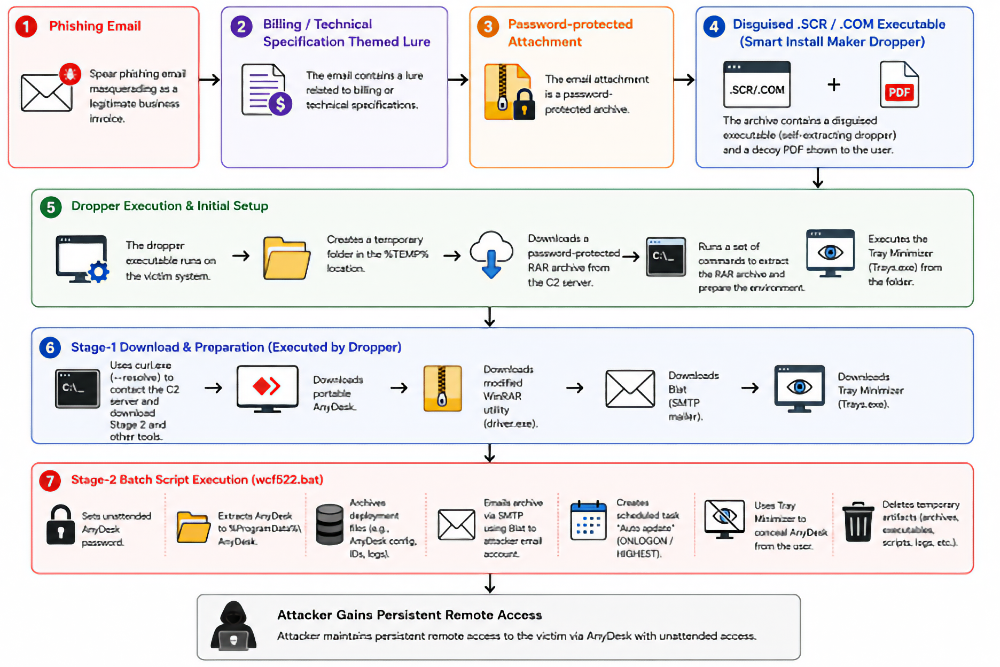
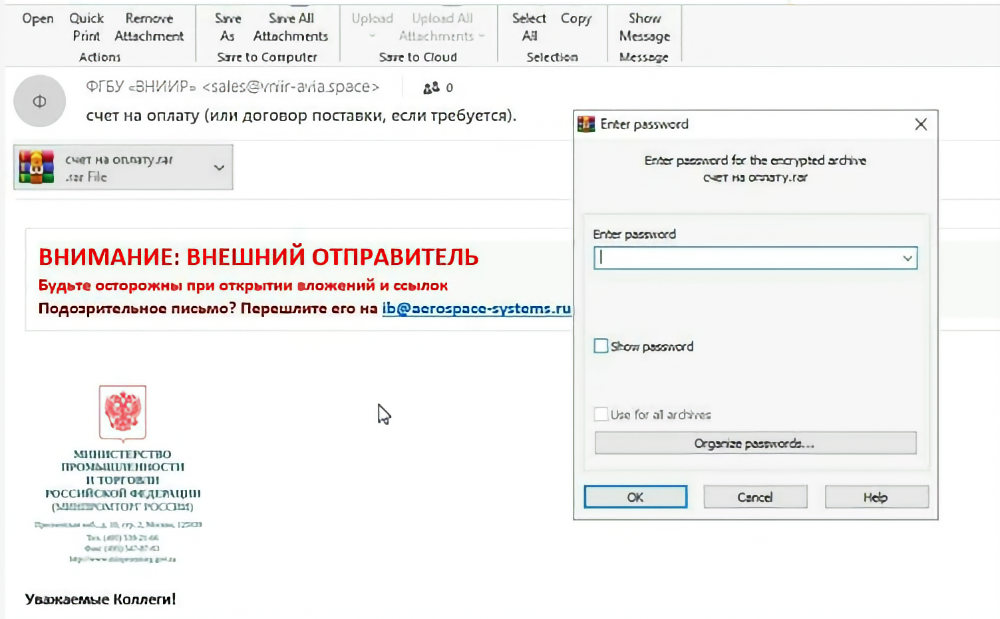
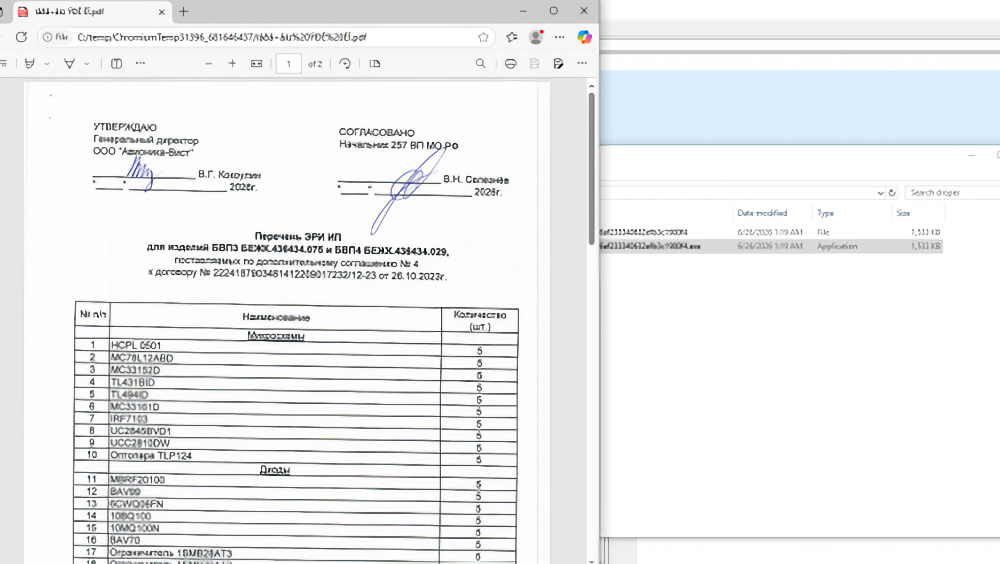
Во вложении лежит запароленный архив. Пароль заботливо указан в тексте письма: пользователю удобно, защитным системам — уже не очень. Внутри находится дроппер, собранный с помощью Smart Install Maker. После запуска он показывает на экране PDF-приманку со счётом, а сам тем временем распаковывает файлы во временную папку и тянет с командного сервера второй архив.
В этом наборе — портативный AnyDesk, почтовая утилита Blat, Tray Minimizer и batch-скрипт. Последний делает всю грязную работу: ждёт около минуты, чтобы пережить песочницы, задаёт фиксированный пароль AnyDesk, копирует его в ProgramData и запускает. После этого операторы могут заходить на машину без лишних вопросов и всплывающих просьб.
Затем скрипт упаковывает настройки AnyDesk в защищённый архив и отправляет их злоумышленникам через Blat по SMTP. Для закрепления создаётся задача с кривым названием Auto apdate, а временные файлы удаляются, чтобы расследователям было веселее копаться в следах.
Seqrite подозревает связь с группой Rare Werewolf, также известной как Librarian Ghouls и Rezet. Её активность фиксируют как минимум с 2019 года, а среди целей ранее были организации в России, Беларуси и Казахстане, включая аэрокосмический сектор и тяжёлую промышленность.
Главная фишка атаки — минимум экзотики. Вместо редкого вредоноса используются легитимные инструменты: AnyDesk, Blat и переименованный WinRAR.



