






Исследователи обнаружили новую Android-платформу для удалённого доступа под названием Glitch SPY, которая распространяется через фейковый сайт аренды квартир и домов. Пользователю предлагают скачать приложение для бронирования и связи с владельцами жилья, а на деле подсовывают вредоносный APK.
Схема начинается с загрузчика Brokewell Android Loader. Он показывает вполне правдоподобный интерфейс сервиса аренды, просит разрешить установку из неизвестных источников, а затем незаметно разворачивает на устройстве Glitch SPY.
Главный рычаг управления — злоупотребление специальными возможностями Android (Accessibility Service). После выдачи этих прав троян получает почти полный контроль над смартфоном: может читать содержимое экрана, нажимать кнопки, выполнять жесты, подтверждать разрешения, взаимодействовать с экраном блокировки и помогать операторам проводить мошеннические операции прямо с устройства жертвы.
По данным Cyble, Glitch SPY поддерживает более 70 команд. Среди них есть, например, трансляция экрана, скриншоты, кейлоггинг, кража СМС и контактов, отслеживание геолокации, запись с камеры и микрофона, управление файлами, выполнение шелл-команд и изменение настроек администрирования устройства.
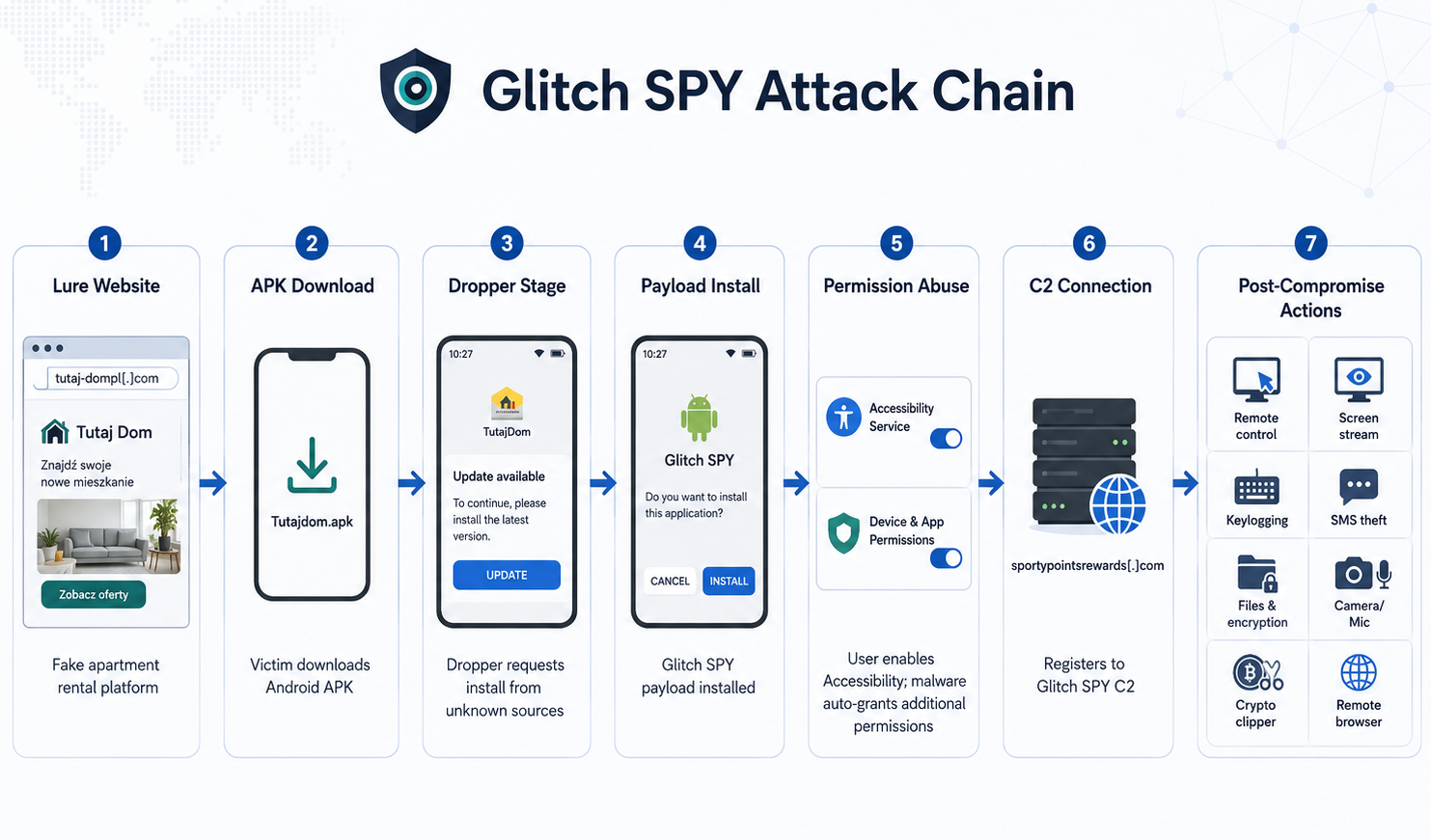
Отдельная неприятность — встроенный клиппер. Если пользователь копирует адрес криптокошелька, вредонос распознает популярные форматы Bitcoin, Ethereum, TRON и других сетей, после чего подменяет адрес на кошелек злоумышленников. Перевод вроде бы отправлен куда надо, но деньги уезжают совсем не туда.
Еще одна опасная функция — скрытый браузер на базе WebView. Атакующие могут открывать сайты, заполнять формы, нажимать элементы и выполнять JavaScript с IP-адреса жертвы и с ее активными сессиями. Для антифрода это выглядит куда убедительнее, чем вход с чужого устройства.
Исследователи также нашли админ-панели с брендингом Glitch SPY, что указывает на инфраструктуру билдера. Операторы могут менять название приложения, пакет, иконку, страницу, набор функций и уведомления в Telegram.