













Пока вокруг национального мессенджера МАКС продолжаются споры, VK готовит масштабное обновление парка техники. Холдинг объявил закупку около 1200 ноутбуков Apple MacBook для разработки и тестирования сервисов. Лэптопы предназначены для компаний «ВК», «Мах» и «Единое видео», которые занимаются развитием мессенджера МАКС и платформы «VK Видео».
Как сообщает CNews со ссылкой на данные площадки «Росэлторг», общая стоимость закупки превышает 2,8 млн долларов.
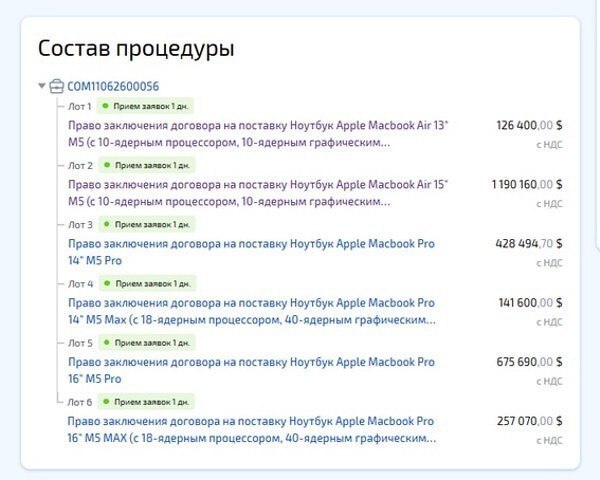
Самый крупный лот включает 700 ноутбуков. Из них 607 получит ООО «ВК», 29 — ООО «Мах» и ещё 60 — ООО «Единое видео». Начальная цена контракта составляет около 1,2 млн долларов.
В списке техники есть как относительно базовые модели MacBook Air, так и топовые MacBook Pro на процессорах Apple M5 Max с 64 ГБ оперативной памяти и SSD объёмом 2 ТБ. Такие устройства планируют использовать в подразделениях, связанных с разработкой и видеосервисами.
Но ноутбуками дело не ограничивается. VK также закупает десятки телевизоров разных производителей и операционных систем — от Tizen и webOS до «Салют ТВ» и WildRed. Кроме того, в перечне фигурируют Apple TV 4K, Android-приставки Xiaomi, IPTV-оборудование, Raspberry Pi и различные аксессуары для тестирования.
Ещё один контракт стоимостью 183 млн рублей включает смартфоны, планшеты, игровые консоли, AV-оборудование и гарнитуры. Вся техника должна быть новой и поставляться с гарантией не менее года.
В VK объясняют закупки следующим образом: оборудование нужно для регулярного обновления рабочих мест сотрудников и тестирования сервисов на разных устройствах, включая устаревшие модели.
Однако внимание к этим тендерам привлекает другой факт. Развитие МАКС и связанных с ним проектов финансируется в том числе за счёт государственных средств. В 2025 году на развитие мессенджера МАКС и видеоплатформы на базе «VK Видео» было выделено около 40 млрд рублей.
На этом фоне особенно интересно выглядит недавняя история с приложением МАКС. В начале июня Apple без объяснения причин удалила мессенджер из App Store. В VK заявили, что уже ведут переговоры с компанией и работают над возвращением приложения в магазин.



