







Специалисты в области кибербезопасности предупреждают об опасности QR-кодов, которые злоумышленники могут использовать в связке с социальной инженерией. Такие схемы позволяют открывать аккаунты пользователей онлайн-банкинга, опустошать банковские счета жертв, а также устанавливать вредоносные программы и внедряться в корпоративные системы.
Эксперты называют QR-коды идеальным вектором атаки, поскольку многие доверяют им и недооценивают их вредоносный потенциал. В исследовании компании MobileIron чётко прослеживается растущая популярность QR-кодов как одного из способов атаки. Специалисты опросили более 2100 клиентов и выяснили интересные детали в отношении использования QR-кодов.
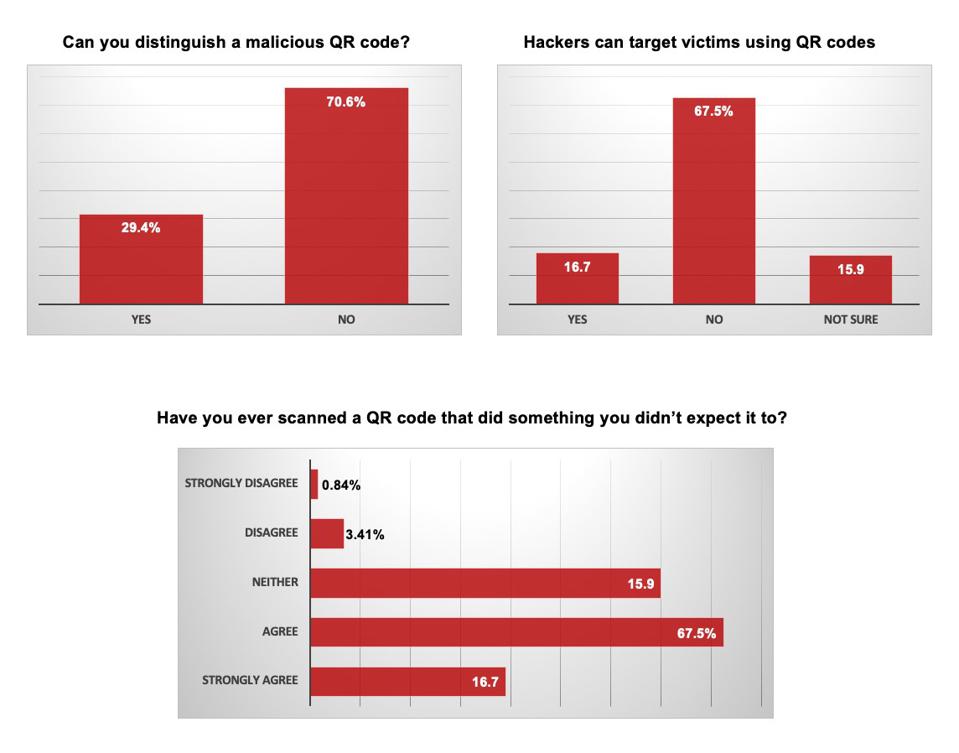
Например, 71% респондентов не может отличить вредоносный QR-код от безобидного. При этом почти 17% сталкивались с ситуацией, в которой именно такие коды перенаправляли их мобильные устройства на подозрительные сайты.
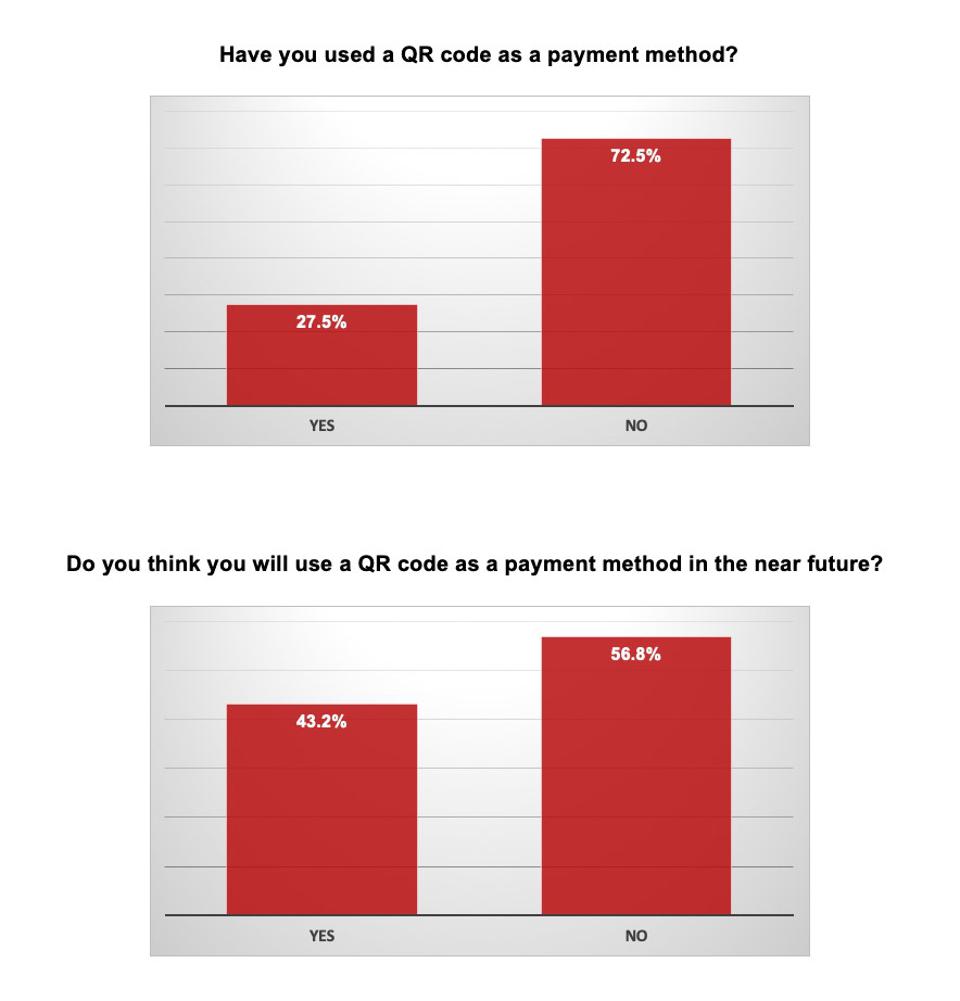
По данным American Express, в 2020 году аналитики отметили рост популярности QR-кодов. Например, 27% опрошенных американцев и британцев совершали транзакции при помощи этих кодов.
При этом команда MobileIron нашла десять способов взломать мобильное устройство пользователя с помощью сгенерированных за считаные секунды QR-кодов. Например, потенциальный атакующий может получить доступ к списку контактов, электронной почте, текстовым сообщениям, геолокации, взломать ваш аккаунт в банковской системе и многое другое.

В MobileIron убеждены, что QR-коды являются уже частью нашей жизни, и именно поэтому важно учитывать их потенциальную опасность.






