















Сайты GitHub, Apple и Google снова открываются у пользователей в России. Сервисы были недоступны около часа, после чего соединение восстановилось без каких-либо официальных объяснений.
Проблемы начались примерно в 10:00 по московскому времени. GitHub не открывался с российских IP-адресов, не работал доступ к репозиториям и могли возникать сбои при выполнении Git-операций. При подключении через иностранные IP платформа продолжала работать штатно.
Перебои подтверждал сервис Detector404, отслеживающий пользовательские жалобы. Одновременно возникли трудности с доступом к официальным сайтам Apple и Google: страницы либо зависали на бесконечной загрузке, либо выдавали ошибку. Соединение устанавливалось с переменным успехом.
Теперь все три ресурса снова доступны. Таким образом, глобальные сервисы исчезли из российского сегмента интернета примерно на час, а затем так же внезапно вернулись.
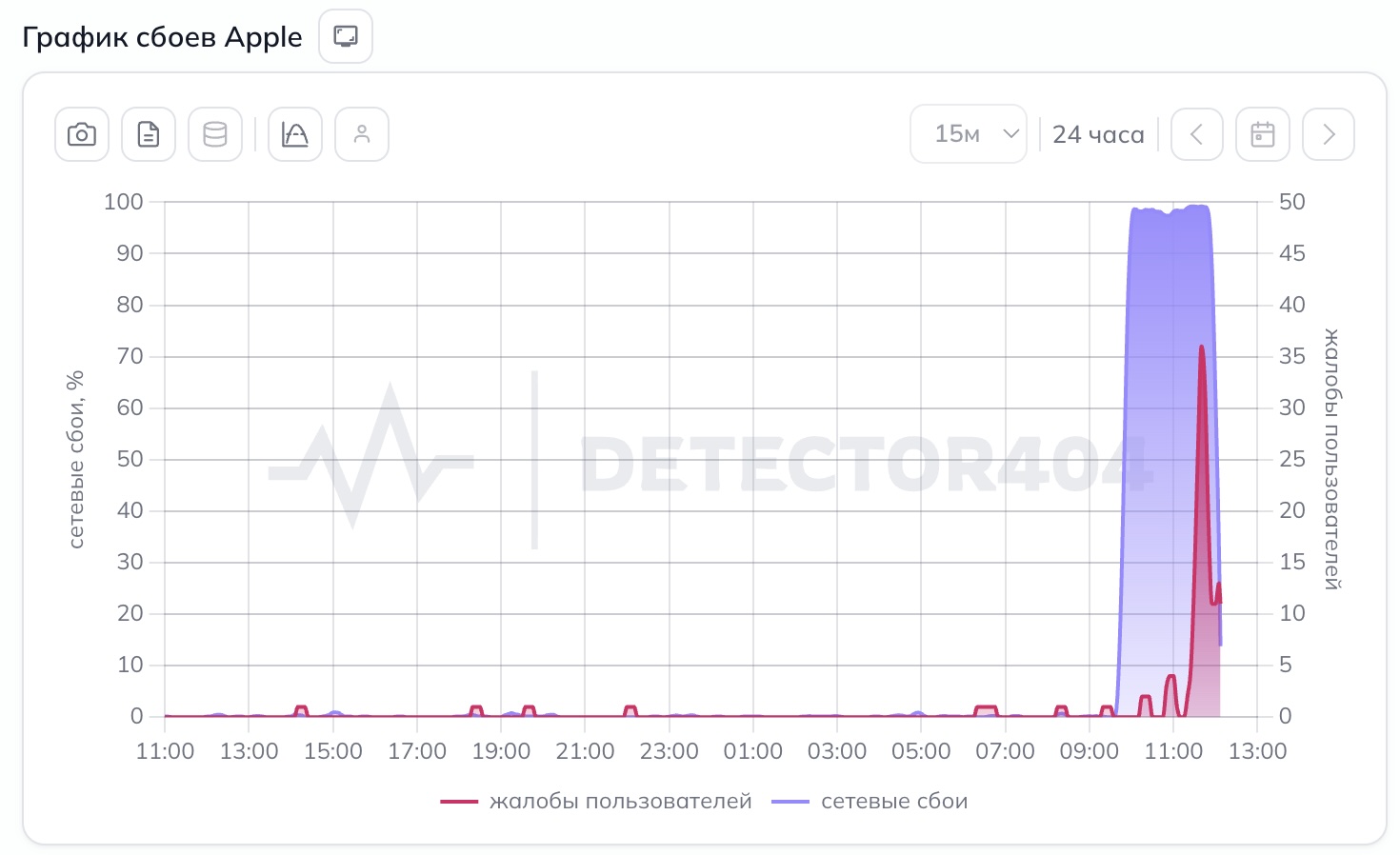
Причина произошедшего остается неизвестной. GitHub, Apple и Google публично ситуацию не комментировали. Роскомнадзор также пока не сообщил, были ли перебои связаны с техническим сбоем, маршрутизацией или ограничениями доступа.



