Специалисты Рурского университета в Бохуме утверждают, что им удалось сломать систему электронных подписей и создать фейковые сигнатуры для большинства десктопных приложений для просмотра файлов PDF.
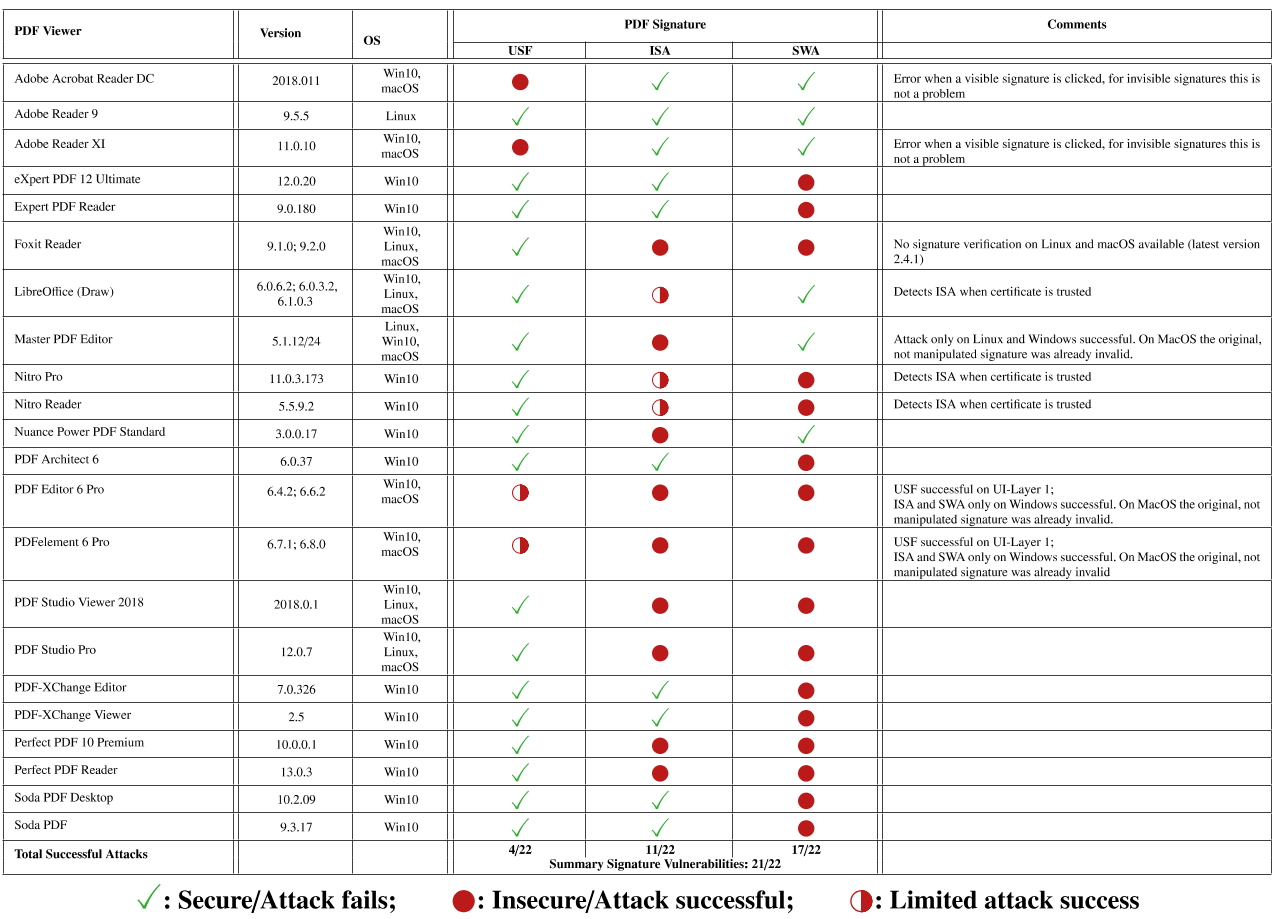
В результате способ экспертов сработал в случае с 21 из 22 десктопных PDF-вьюверов. Помимо этого, исследователи также обошли защитные меры пяти из семи онлайн-сервисов для цифровой подписи PDF.
Из популярных приложений такого класса можно отметить Adobe Acrobat Reader, Foxit Reader и LibreOffice, а примеры вышеназванных сервисов — DocuSign и Evotrust.
Группа из пяти экспертов работала над этой техникой с октября 2018 года. И теперь им удалось выявить уязвимые приложения и онлайн-сервисы. Специалисты дождались выхода патчей от разработчиков, и лишь потом открыли результаты своего исследования.
Исследователи отмечают, что цифровые подписи PDF крайне важны. Именно поэтому они были готовы ждать целые месяцы, пока компании выпускают патчи. Их можно понять, ведь подписанный цифровой подписью PDF-документ может использоваться в суде.
Более того, такие документы также используют для подтверждения финансовых транзакций и пресс-релизов государственного уровня.
Если у злоумышленников будет возможность подделать цифровую подпись, появится возможность для кражи огромного количества денег. Также киберпреступники, используя фейковую подпись для документа PDF, могут посеять хаос среди компаний.
Всего эксперты описали три важнейшие уязвимости:
- Universal Signature Forgery (USF) — позволяет атакующим воздействовать на процесс валидации подписи. Таким образом, пользователю отобразится поддельное сообщение о достоверности подписи.
- Incremental Saving Attack (ISA) — позволяет добавить дополнительный контент на уже подписанный документ PDF.
- Signature Wrapping (SWA) — схожая с ISA уязвимость, однако здесь используется система «оборачивания» вокруг дополнительного контента злоумышленника.
«На данный момент мы не встречали подтверждение того, что эксплойты для этих брешей используются в реальных атаках», — пишут эксперты.