














С 3 июня 2026 года десктопное приложение «Яндекс Диск» для Windows и macOS перестанет полноценно работать без подписки. Бесплатным пользователям отключат облачные функции в десктопном клиенте, включая синхронизацию файлов между компьютером и облаком.
Сам «Яндекс Диск» при этом не закрывается: файлы останутся на месте и будут доступны через веб-версию и другие устройства.
Меняется именно доступ к привычному десктопному приложению. То есть облако вроде бы есть, но из программы на компьютере без подписки до него уже не дотянуться.
О нововведении пользователям начали сообщать через всплывающие баннеры в приложении. В них говорится, что с 3 июня программа «Диска» для компьютера будет доступна только в тарифе «Яндекс 360».
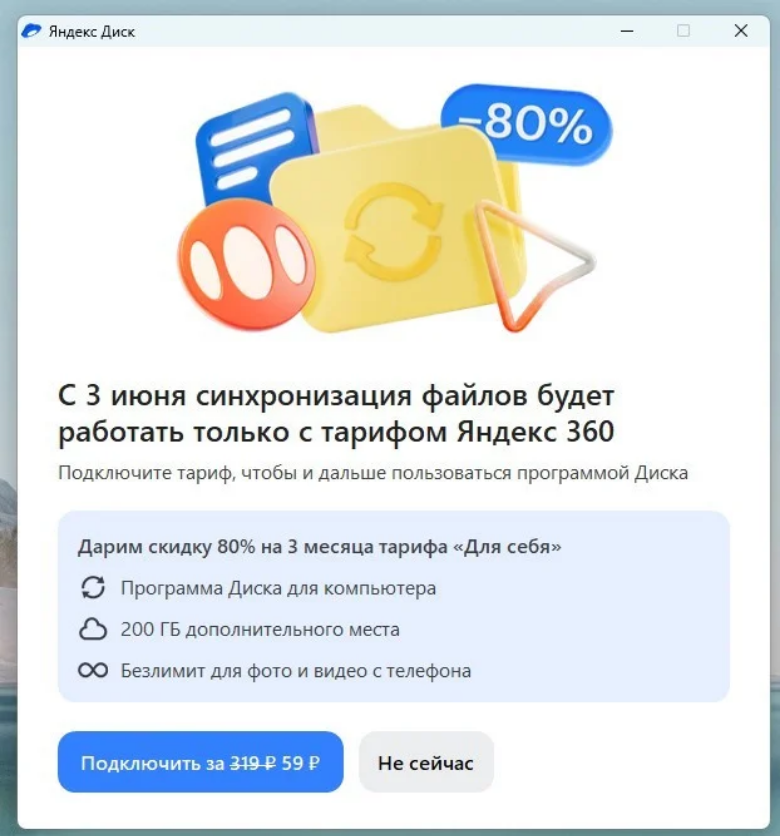
Без подписки в десктопном клиенте можно будет открыть только те файлы, которые уже заранее сохранены на компьютере. Чтобы снова работать с облаком напрямую из программы, понадобится подключить «Яндекс 360». Например, подписка стоит от 319 рублей в месяц и расширяет хранилище до 200 ГБ.
В «Яндексе» объясняют изменения тем, что пользователи всё чаще используют приложение «Диска» для переноса больших файлов, а такие операции требуют больше серверных ресурсов. На переходный период компания предлагает скидку 80% на «Яндекс 360» в течение трёх месяцев.
Пользователи, ожидаемо, не в восторге. Для многих синхронизация через десктопный клиент годами была базовой функцией, а теперь она уезжает за пейволл. И особенно весело это выглядит на фоне конкурентов: iCloud, Google Drive, «СберДиск» и другие облачные сервисы всё ещё позволяют пользоваться бесплатным тарифом через приложение, а не только через браузер.



