















У российских разработчиков снова проблемы: пользователи начали жаловаться на проблемы с доступом к PyPI — главному репозиторию пакетов для Python. Именно оттуда pip install обычно тянет библиотеки, без которых современная разработка быстро превращается в квест.
О проблеме написал пользователь Хабра под ником freehabr. По его словам, сайт pypi.org, с которого скачиваются пакеты Python, оказался недоступен у конечных пользователей и на хостингах. Автор утверждает, что проверял доступность сервиса самостоятельно.
Ситуация неприятная не только для любителей Python-скриптов. От экосистемы Python завязана огромная часть современной ИТ-разработки, включая машинное обучение, анализ данных, автоматизацию, DevOps-инструменты и ИИ-проекты. Поэтому проблемы с PyPI — это потенциальный удар по сборкам, деплою и рабочим процессам команд.
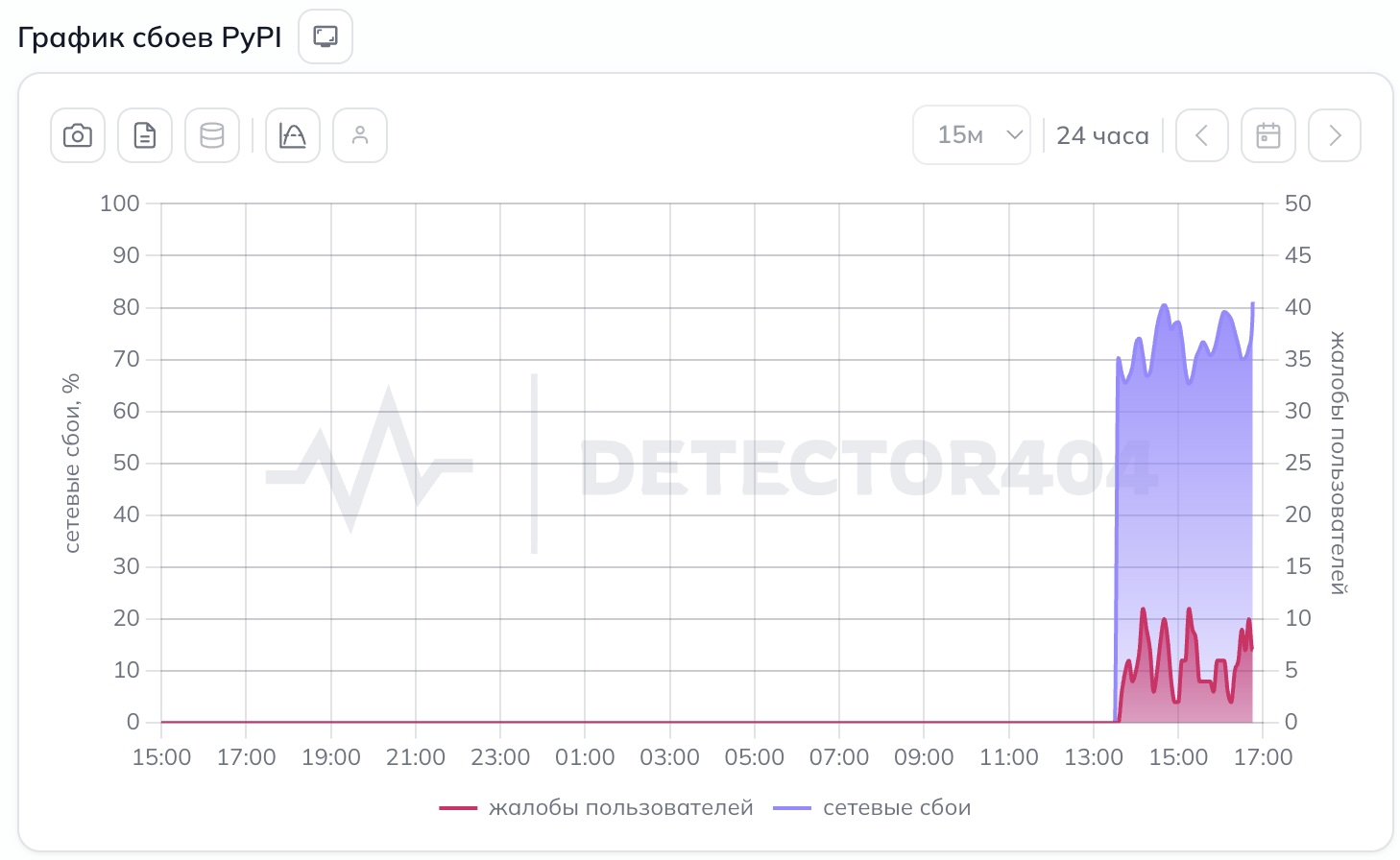
По данным сервисов мониторинга жалоб, за последний час сообщения о проблемах с PyPI поступали из нескольких регионов. Чаще всего пользователи жаловались в Орловской, Курской, Липецкой, Брянской и Тульской областях.
В статистике за последние сутки основная доля обращений пришлась на сбой сайта — 88%. Ещё 5% сообщений касались сбоя мобильного приложения, хотя у PyPI это звучит как отдельный жанр абсурда, и ещё 5% — общего сбоя.
Ранее на Российской общественной инициативе уже появлялись петиции с требованием ограничить блокировки, мешающие работе разработчиков и ИТ-инфраструктуры.
Если PyPI действительно начнёт массово отваливаться, последствия быстро почувствуют не только программисты, но и компании, у которых сборка, тестирование и развёртывание завязаны на Python-пакеты.



