










Apple решила сделать iPhone и iPad менее зависимыми от компьютеров. В iOS 27 и iPadOS 27 появилась новая система восстановления устройства, которая позволит решать часть серьёзных проблем прямо на самом смартфоне или планшете. Речь идёт о полноценном Recovery Mode — аналоге режима восстановления, который уже давно существует на macOS-компьютерах.
Работает это так: если iPhone выключен, пользователю достаточно включить его и продолжать удерживать кнопку питания даже после появления логотипа Apple.
Через некоторое время на экране появится индикатор загрузки, а затем откроется специальное меню восстановления.
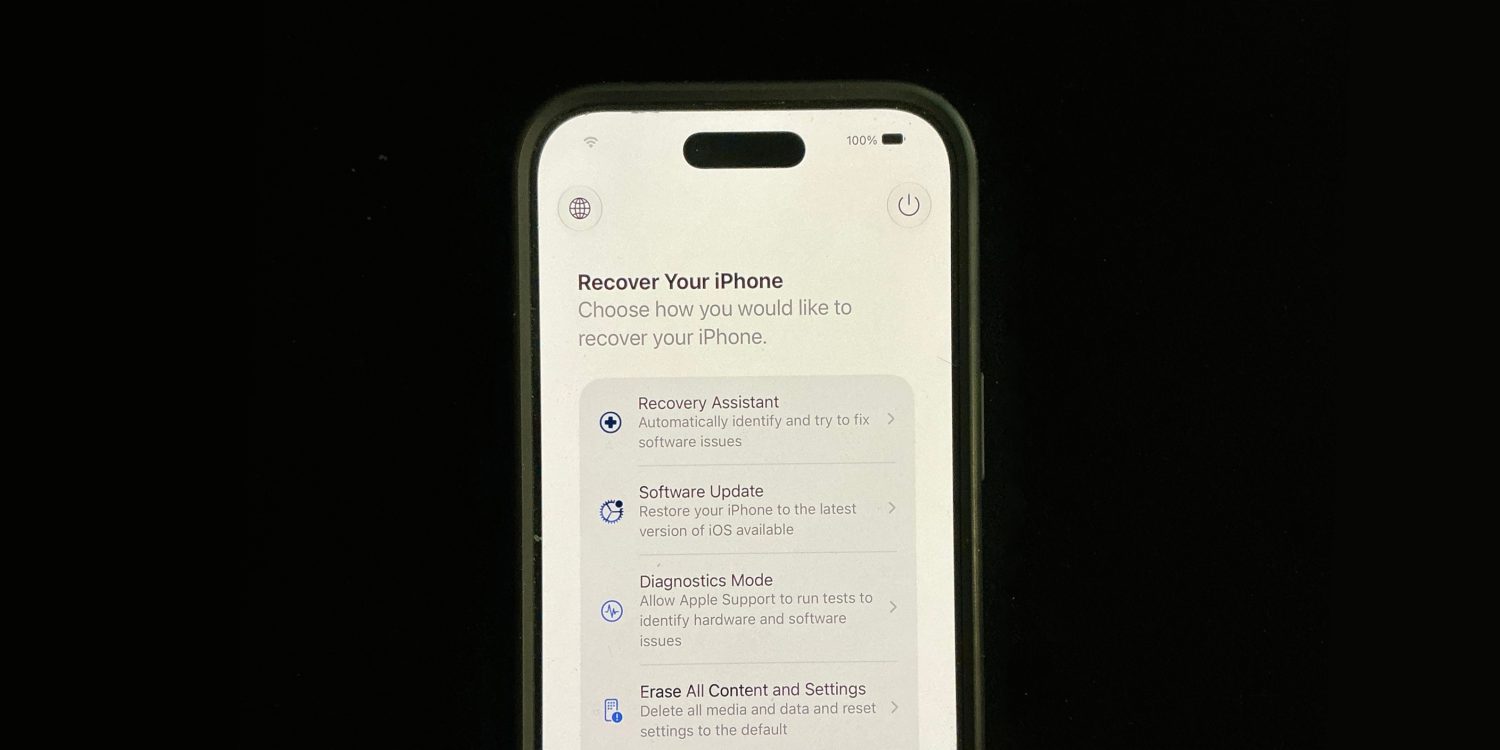
Внутри доступны сразу несколько полезных инструментов. Пользователь сможет установить обновление системы, запустить диагностику устройства, полностью стереть данные, воспользоваться помощником Recovery Assistant или выполнить другие операции по восстановлению.
Источник: 9to5Mac
Любопытно, что новый режим показывает текущий уровень заряда батареи и автоматически подключается к сохранённым сетям Wi-Fi. Отсюда же можно попытаться загрузить устройство в обычном режиме.
Главное новшество заключается в том, что многие аварийные сценарии теперь можно будет исправить без подключения iPhone к компьютеру.
Например, если обновление iOS оборвалось из-за разрядившейся батареи или устройство попало в цикл бесконечной перезагрузки после неудачной установки новой версии системы, раньше пользователям зачастую приходилось искать десктоп и восстанавливать смартфон через DFU-режим.
С выходом iOS 27 часть таких проблем можно будет решить прямо на устройстве. В некоторых случаях Recovery Assistant даже позволит переустановить последнюю стабильную версию операционной системы без использования компьютера.
Конечно, большинству владельцев iPhone этот режим может никогда не понадобиться, но если смартфон внезапно превратится в дорогой кирпич после очередного обновления, шансов вернуть его к жизни станет больше.



