











В Сети появилась информация о том, что мессенджер МАКС якобы получил у Cloudflare статус шпионского приложения. Если такая классификация действительно появилась, это могло бы стать серьёзным репутационным ударом для сервиса: подобные метки учитываются системами безопасности, фильтрации трафика и корпоративной защиты.
В открытых источниках есть обсуждения сетевой активности МАКС, а также жалобы на связанные сервисы в Cloudflare Community, но они не доказывают, что мессенджер официально внесён в категорию spyware.
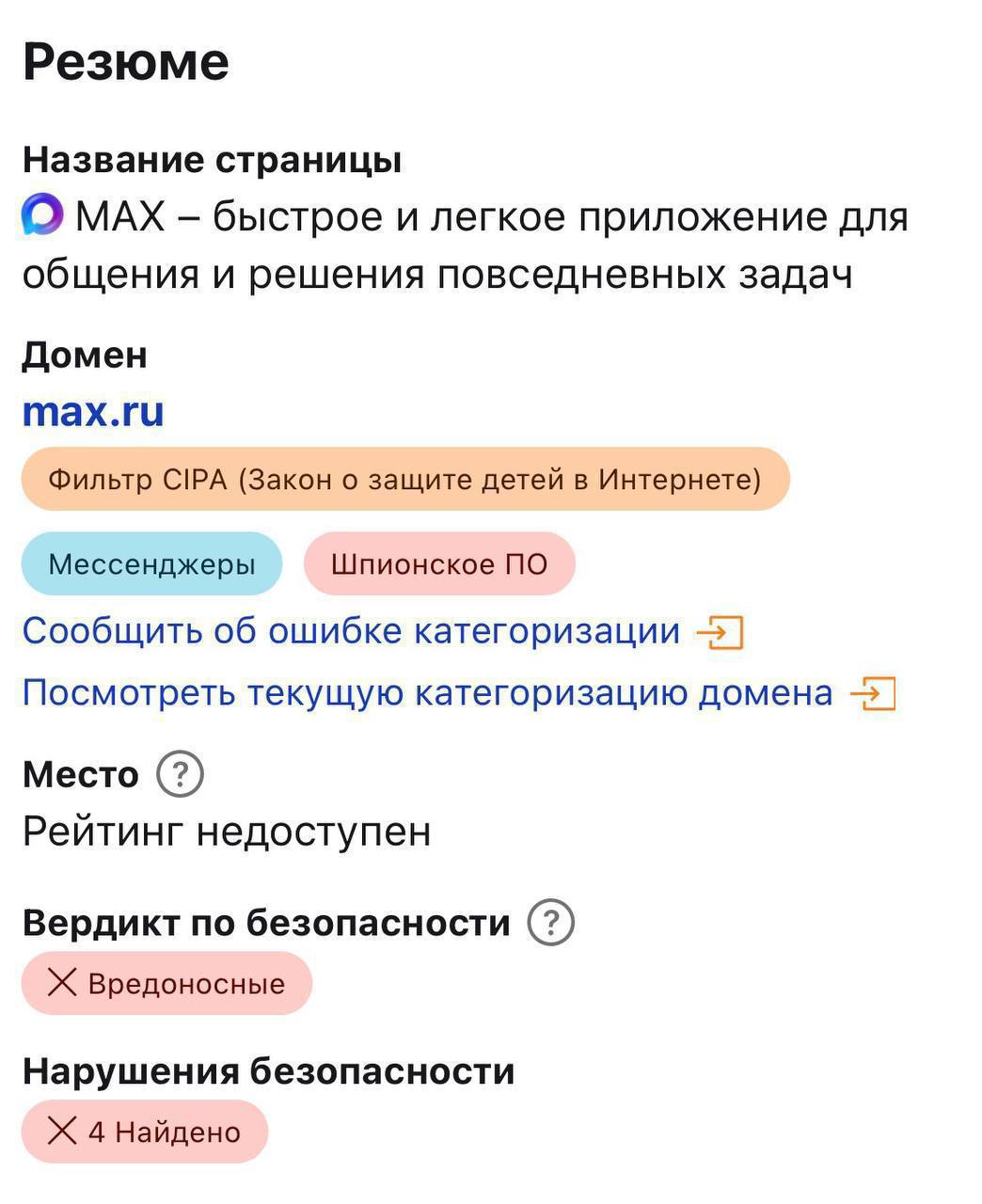
Такая осторожность важна: статус шпионского софта — не просто оценочное слово, а серьёзная техническая и репутационная метка. Она может повлиять на доверие пользователей, отношение ИБ-специалистов и решения платформ, через которые распространяется приложение.
Пока представители МАКС и Cloudflare публично не прокомментировали ситуацию, говорить о санкциях со стороны магазинов приложений или массовой блокировке трафика преждевременно.
Но сам факт появления таких сообщений показывает, что к безопасности и сетевому поведению национального мессенджера сохраняется повышенное внимание.
Пресс-служба VK дала нашему изданию развернутый комментарий:
«Классификация Cloudflare вызвана неверной интерпретацией заголовков запросов к сервисам обыкновенной веб-аналитики сайта max.ru, а не на фактическом анализе кода. MAX регулярно проходит аудиты безопасности, работает с исследователями через программу Bug Bounty и имеет собственный центр безопасности для защиты пользователей от реальных угроз. Все данные пользователей МАХ надежно защищены».
Ранее та же история коснулась Telega.



