















Уязвимость в расширении Adobe Acrobat для Chrome позволяла незаметно вытаскивать переписку, контакты и данные аккаунта из WhatsApp Web (принадлежит корпорации Meta, признанной экстремистской и запрещённой в России). Под ударом могли оказаться около 329 млн браузеров — именно столько установок насчитывает популярное расширение.
Для атаки не требовалось взламывать WhatsApp, красть пароль или заражать компьютер вредоносной программой.
Достаточно было заманить пользователя на внешне безобидную страницу. Дальше всё происходило без лишних вопросов и предупреждений.
Исследователи компании Guardio назвали атаку HermeticReader. В её основе лежала ошибка во внутренней системе обмена сообщениями расширения Adobe. Вредоносный сайт загружал скрытый фрейм и заставлял расширение выполнять команды, не проверяя их источник.
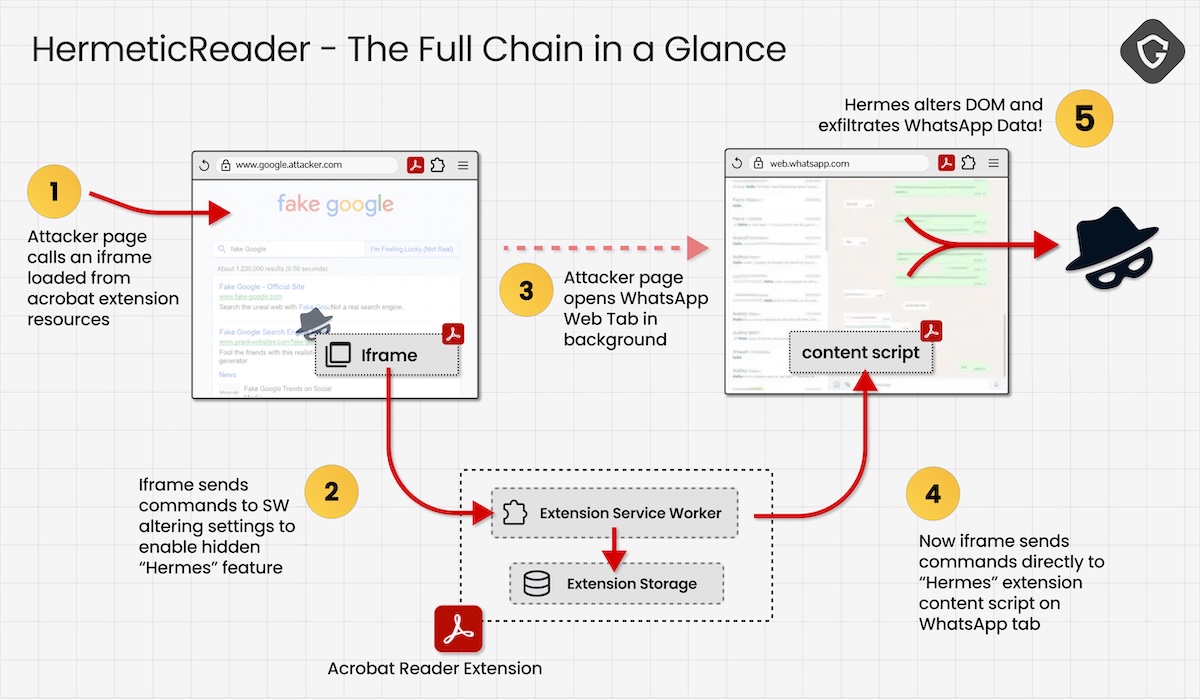
Злоумышленник мог записать данные в локальное хранилище Adobe Acrobat и активировать Hermes — встроенный, но неактивный по умолчанию механизм интеграции. Тот становился мостом к WhatsApp Web и позволял в фоновом режиме собирать личные чаты, контакты и сведения об аккаунте в открытом виде.
Пользователь тем временем просто смотрел обычную веб-страницу и понятия не имел, что расширение для работы с PDF уже читает его мессенджер.
Guardio обнаружила проблему и сообщила о ней Adobe. Компания закрыла уязвимость в июне и присвоила ей идентификатор CVE-2026-48294. В Adobe классифицировали баг как UXSS-уязвимость, приводящую к раскрытию данных между разными сайтами.



