Браузерные ИИ-агенты, которые обещают «сделать всё за пользователя» — от бронирования отелей до онлайн-покупок, — могут оказаться куда менее безопасными, чем кажется. К такому выводу пришли авторы нового исследования, посвящённого рискам конфиденциальности.
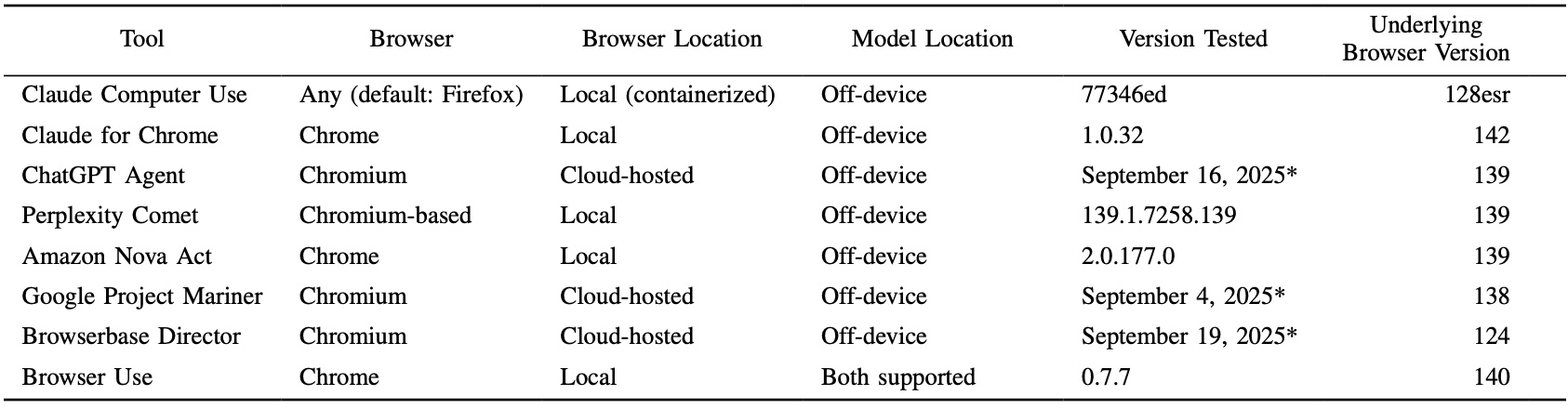
Исследователи изучили (PDF) восемь решений, которые активно развивались или обновлялись в 2025 году.
В выборку вошли ChatGPT Agent, Google Project Mariner, Amazon Nova Act, Perplexity Comet, Browserbase Director, Browser Use, Claude Computer Use и Claude for Chrome. Итог получился тревожным: в каждом из продуктов нашли как минимум одну уязвимость, а всего зафиксировали 30 проблем.
Одна из ключевых претензий — архитектура таких агентов. В большинстве случаев языковая модель работает не на устройстве пользователя, а на серверах разработчика. Это означает, что данные о состоянии браузера, поисковых запросах и содержимом страниц передаются третьей стороне. Формально провайдеры обещают ограничения на использование этих данных, но на практике пользователю остаётся лишь доверять политике сервиса.
Дополнительный риск — устаревшие браузеры. В одном случае агент использовал версию браузера, отстававшую на 16 крупных релизов, с уже известными уязвимостями. Такой софт может быть легко атакован через вредоносный сайт.
Ещё одна проблема — отношение агентов к опасным сайтам. Многие из них игнорируют стандартные браузерные предупреждения. В ходе тестов шесть из восьми агентов никак не сообщили пользователю, что открытая страница входит в списки фишинговых ресурсов. В результате ИИ может спокойно продолжать «выполнять задачу» — вплоть до ввода логинов и паролей на поддельных страницах.
Нашлись и проблемы с TLS-сертификатами: некоторые агенты не предупреждали об отозванных, просроченных или самоподписанных сертификатах. В одном случае модель просто «кликнула» предупреждение и продолжила работу, что открывает путь к атакам типа «Человек посередине».
Исследование показало, что браузерные агенты могут ослаблять защиту от межсайтового трекинга. Часть решений некорректно изолирует сторонние данные вроде cookies, что упрощает отслеживание активности пользователя на разных сайтах. Некоторые агенты по умолчанию сохраняют профильные данные — причём не всегда уведомляя об этом и не предлагая способ очистки.
Автоматизация доходит и до диалогов конфиденциальности. В тестах несколько агентов самостоятельно нажимали «Принять все cookies», даже когда рядом была кнопка «Отклонить». В одном случае это делалось ради продолжения задачи, в другом — из-за расширения, автоматически подавляющего cookie-баннеры.
С разрешениями на уведомления ситуация тоже неоднозначная: один агент просто выдавал доступ без спроса, другие игнорировали запросы, если могли продолжить работу, или действовали по стандартным настройкам браузера.
Самые чувствительные находки касаются утечек персональных данных. Исследователи дали агентам вымышленную личность и проверили, будут ли они делиться этой информацией с сайтами. Результат — шесть уязвимостей, связанных с раскрытием данных.
Некоторые агенты передавали информацию даже когда это не требовалось для выполнения задачи. В ход шли имейл-адреса, почтовые индексы, демографические данные, а в одном случае агент попытался отправить номер банковской карты. Были и примеры, когда ZIP-код вычислялся по IP-адресу и использовался для доступа к «локальным ценам».
Когда данные всё же не передавались, агенты либо подставляли заглушки, либо прямо сообщали, что информация недоступна — даже если это мешало завершить задачу.
Авторы исследования подчёркивают: проблема не в самой идее browser agents, а в том, как они спроектированы. Они советуют разработчикам активнее привлекать специалистов по приватности, регулярно прогонять решения через автоматизированные тесты и аккуратнее обращаться с механизмами защиты, которые уже есть в браузерах.