













WhatsApp (принадлежит Meta, признанной экстремистской и запрещенной в России) готовит новый способ резервного копирования переписок. Сейчас пользователи обычно сохраняют бэкапы в Google Drive на Android или iCloud на iPhone, но Meta хочет добавить ещё один вариант — хранение резервных копий на собственных серверах.
По данным WABetaInfo, в приложении может появиться выбор поставщика резервного копирования: например, Google или WhatsApp.
При этом компания обещает защитить такие копии сквозным шифрованием, чтобы доступ к данным не получила даже сама Meta.
Для защиты чатов будет использоваться ключи доступа (passkey). Пользователь сможет открывать доступ к резервной копии с помощью отпечатка пальца или распознавания лица.
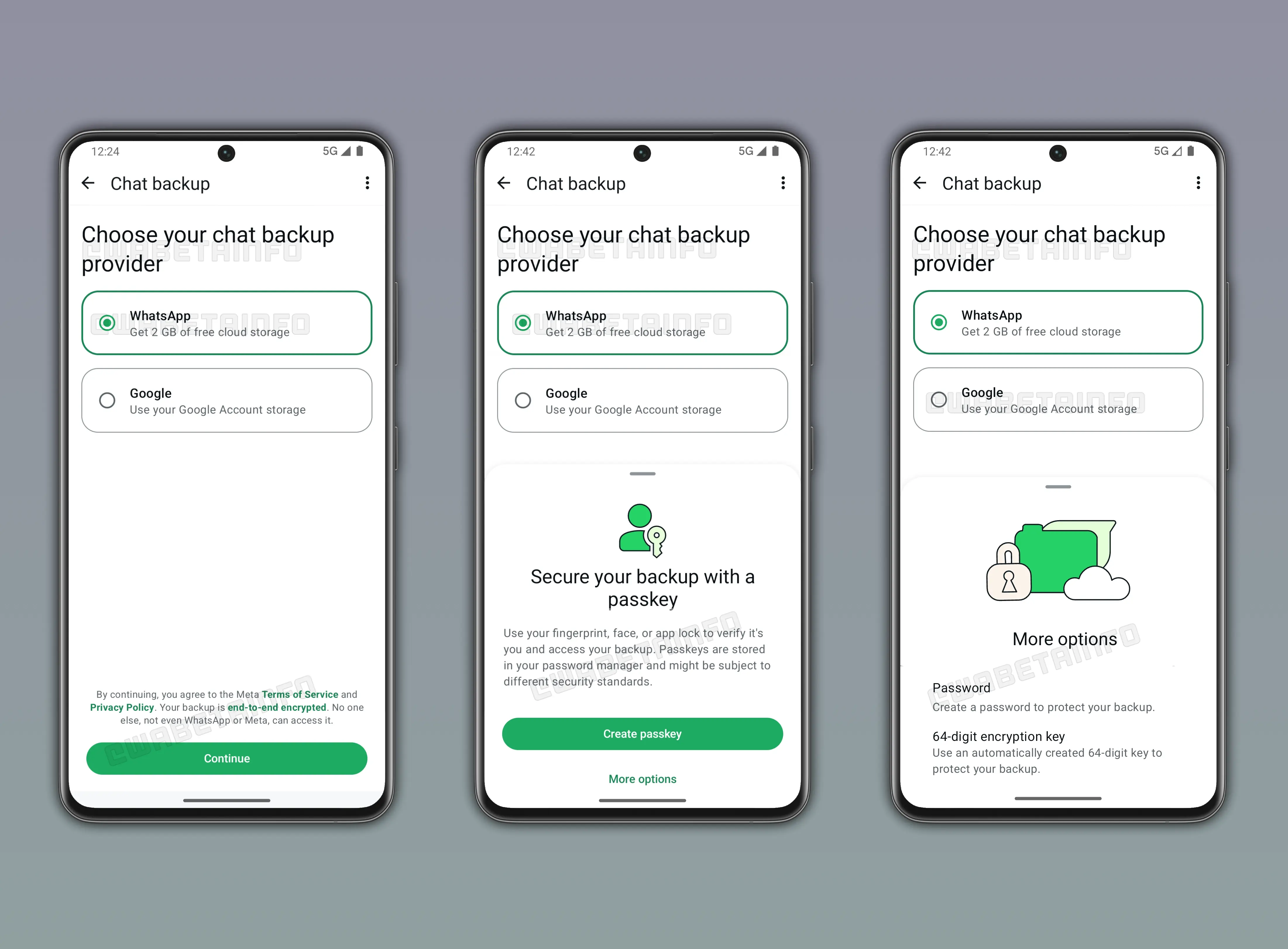
Сам passkey будет храниться в менеджере паролей. Кроме того, резервные копии будут шифроваться с помощью 64-значного ключа.
Ожидается, что у нового сервиса будет бесплатный и платный варианты. В бесплатном тарифе пользователям могут дать 2 ГБ для резервных копий, а в платном — 50 ГБ за $0,99 (74 рубля).
Такой вариант может быть особенно удобен для тех, кто не хочет занимать место в Google Drive или iCloud. Если резервные копии можно будет перенести в инфраструктуру WhatsApp, пользователи смогут освободить облачное хранилище Google или Apple.
При этом пока остаются вопросы. Например, неизвестно, получат ли бесплатные 2 ГБ все пользователи или только подписчики WhatsApp Plus. Также неясно, станет ли платный тариф частью этой подписки. Функция пока находится в разработке, поэтому детали могут измениться до релиза.
Напомним, WhatsApp работает над новой функцией для Android — пузырьками уведомлений.



