














Киберпреступники нашли свежий способ угонять телеграм-аккаунты россиян. На этот раз в качестве приманки используются фейковые сайты крупных сетей АЗС, где обещают зарезервировать до 20 литров топлива без очередей и талонов.
О новой схеме сообщили специалисты компании Эфшесть/F6. По данным исследователей, злоумышленники создают поддельные сайты под брендами известных автозаправочных сетей, в том числе работающих на территории Крыма.
Посетителям предлагают оформить предварительную бронь топлива и приехать на АЗС к назначенному времени. Легенда выглядит убедительно: пользователю обещают 20 литров бензина, персональный номер брони и QR-код для получения топлива без ожидания в очереди.
Для оформления заявки жертву просят указать номер телефона, привязанный к Telegram, а затем ввести код подтверждения, который приходит в мессенджер. На самом деле этот код нужен вовсе не для получения бензина, он используется для входа в телеграм-аккаунт жертвы.
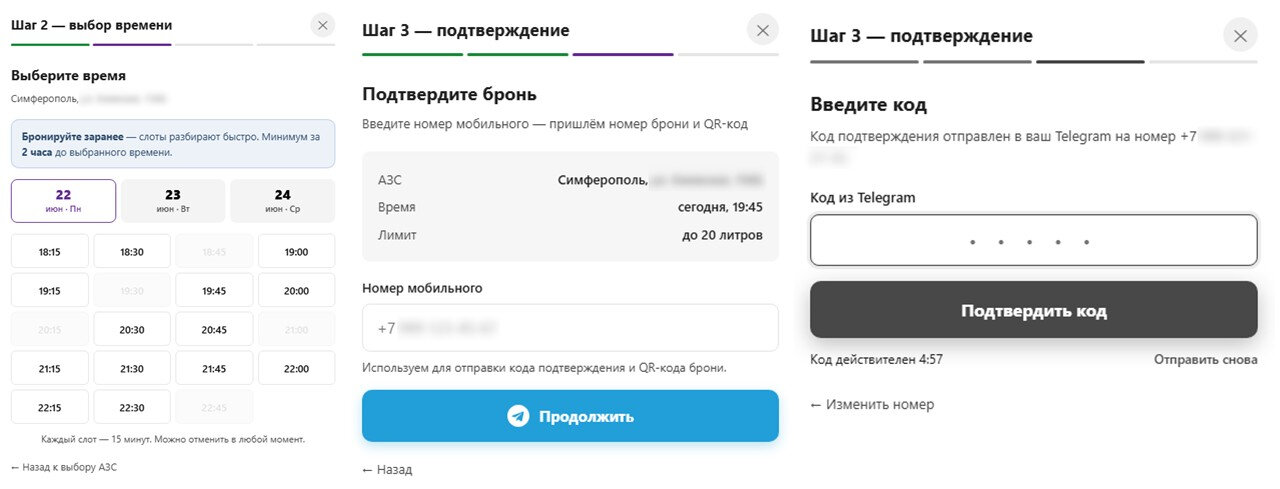
После ввода кода злоумышленники получают полный контроль над учетной записью.
Дальше сценариев может быть несколько. Киберпреступники могут читать переписку и получать доступ к файлам, рассылать сообщения контактам с просьбами занять денег, распространять вредоносные ссылки или просто продать угнанный аккаунт на теневых площадках.
В Эфшесть/F6 отмечают, что мошенники традиционно подстраиваются под актуальную информационную повестку и используют темы, которые вызывают у людей повышенный интерес. В данном случае ставка сделана на желание сэкономить время и получить топливо без очередей.
Эксперты напоминают простое правило: никакая акция, скидка или бронь бензина не требует передачи кодов из Telegram. Если сайт просит ввести код подтверждения из мессенджера, речь почти наверняка идет о попытке угона аккаунта.



