













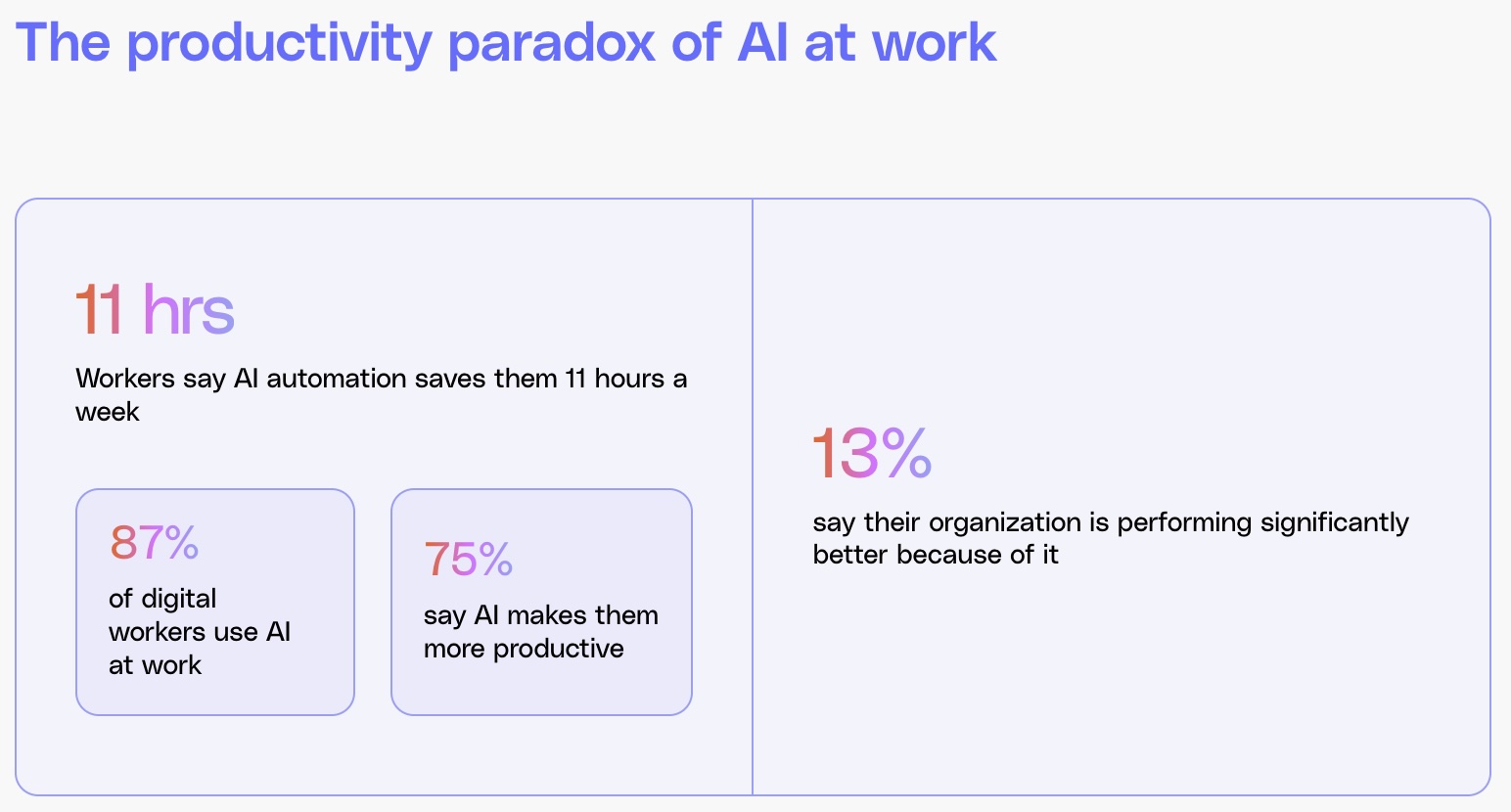
Искусственный интеллект попал в неудобную статистику. Новое исследование Work AI Institute показало, что сотрудники действительно экономят время благодаря ИИ — в среднем около 11 часов в неделю. Но есть нюанс: более шести часов из этой экономии приходится тратить на проверку, исправление и контроль работы самого ИИ.
Исследование охватило 6000 офисных сотрудников из США, Великобритании и Австралии.
Опрос показал, что 75% работников заметили рост личной продуктивности после внедрения ИИ-инструментов. Однако только 13% компаний сообщили о заметном росте бизнеса благодаря этим технологиям.
Получается любопытный парадокс. Формально сотрудники работают быстрее, но бизнес почему-то не получает сопоставимой выгоды.
По словам профессора Калифорнийского университета Пола Леонарди, многие недооценивают объём скрытой работы, которая появляется вместе с ИИ. Нужно собирать данные, подготавливать контекст, перепроверять ответы чат-ботов, искать ошибки и дорабатывать результаты вручную.
Фактически современные сотрудники всё чаще выступают не исполнителями, а менеджерами собственных цифровых помощников.
Согласно исследованию, 37% времени взаимодействия с ИИ уходит непосредственно на работу с ботами, а ещё 36% — на применение полученных результатов в реальных задачах. Более того, 41% опрошенных признались, что не могут объяснить, каким образом ИИ пришёл к своим выводам.
Авторы приводят показательный пример. Молодой разработчик перед уходом домой интегрировал в проект тысячи строк кода, сгенерированного ИИ. После этого система перестала работать, а разбираться в причинах пришлось старшему инженеру. Сам автор изменений не смог объяснить, что именно сделал искусственный интеллект.




