















Исследователи из Group-IB обнаружили новый стилер для macOS, который выбивает пароль из жертвы почти буквально. ClickLock Stealer блокирует нормальную работу компьютера, пока пользователь не введёт настоящие данные от учётной записи. С мая 2026 года от вредоноса пострадали не менее 100 человек в 33 странах.
Атака начинается с поддельной проверки Cloudflare. Пользователю предлагают вставить команду в Терминал, после чего скрипт показывает фальшивую проверку браузера с прогресс-баром.
Пока будущая жертва любуется анимацией, вредонос загружает четыре модуля со взломанных сайтов на WordPress. Затем появляется убедительное окно macOS с именем пользователя и просьбой ввести пароль. ClickLock проверяет его через локальную службу каталогов и отправляет операторам только рабочие данные.
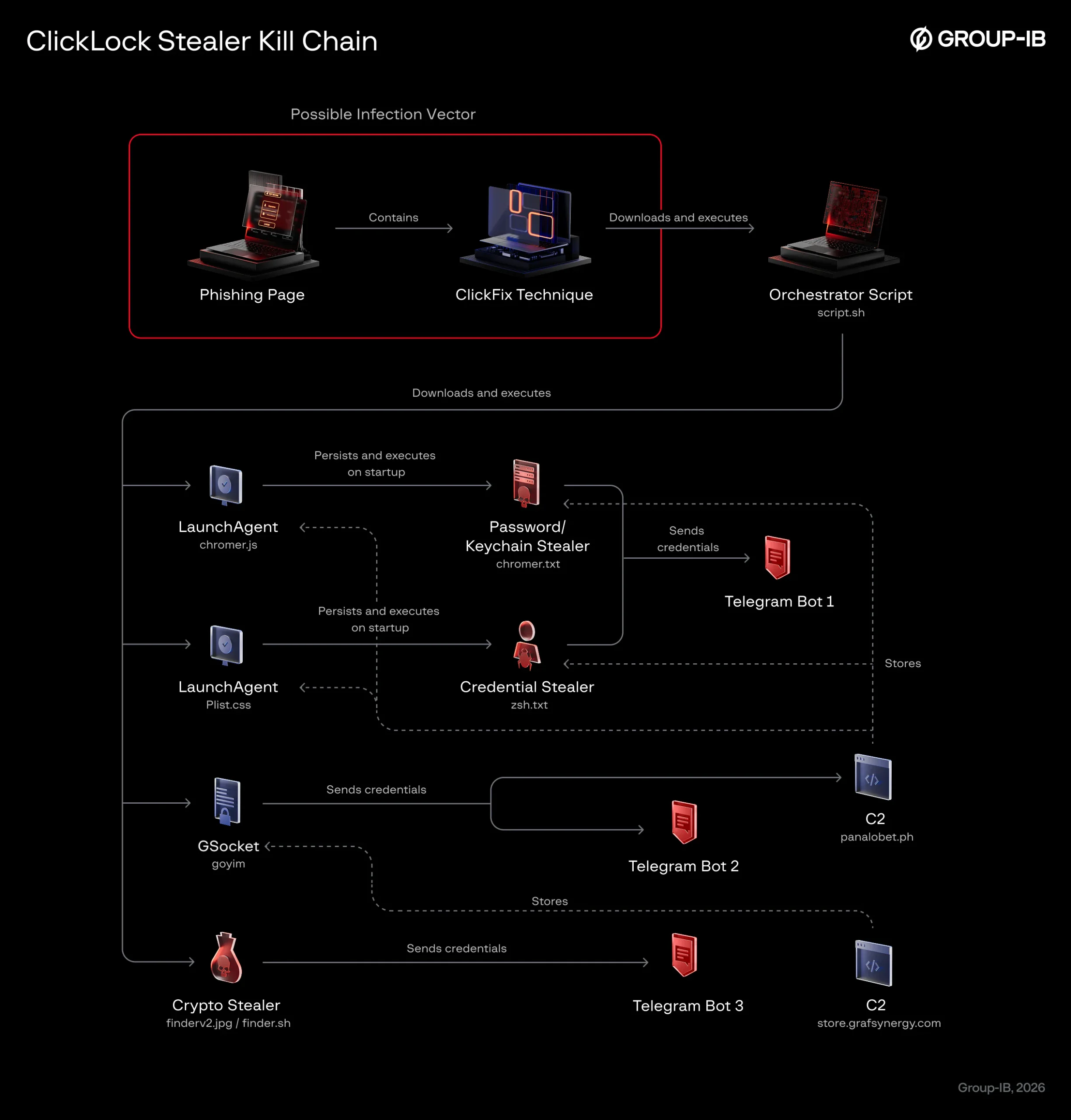
Нажать «Отмена» и уйти не получится. Вредонос устанавливает два LaunchAgent-модуля, которые активируются при следующем входе. Один каждые 210 миллисекунд закрывает все видимые приложения, оставляя на экране лишь окно ввода пароля.
Второй таким же способом заставляет жертву подтвердить настоящий запрос Keychain, чтобы украсть ключ Chrome Safe Storage. Отдельный процесс на несколько часов глушит Центр уведомлений.
Добыча получается внушительной: данные восьми браузеров, расширений 31 криптокошелька и семи менеджеров паролей, восемь настольных кошельков, Keychain, история команд, FTP-учётки и адреса в шести блокчейнах. Украденное уходит через Telegram-ботов и взломанные домены. В системе остаётся замаскированный бэкдор GSocket.
Большинство модулей после работы удаляются и подделывают временные метки файлов. Кто стоит за кампанией, пока неизвестно. Связь с техникой ClickFix исследователи считают весьма вероятной, но сами фишинговые страницы не наблюдали.



