В «Лаборатории Касперского» проанализировали летние атаки на государственные и индустриальные организации РФ, а также образцы Windows-троянов, с помощью которых злоумышленники воровали данные.
Имейл-рассылки, нацеленные на внедрение бэкдоров, были зафиксированы в начале июня. К середине августа авторы атак обновили основной вариант зловреда, расширив набор функций для кражи данных.
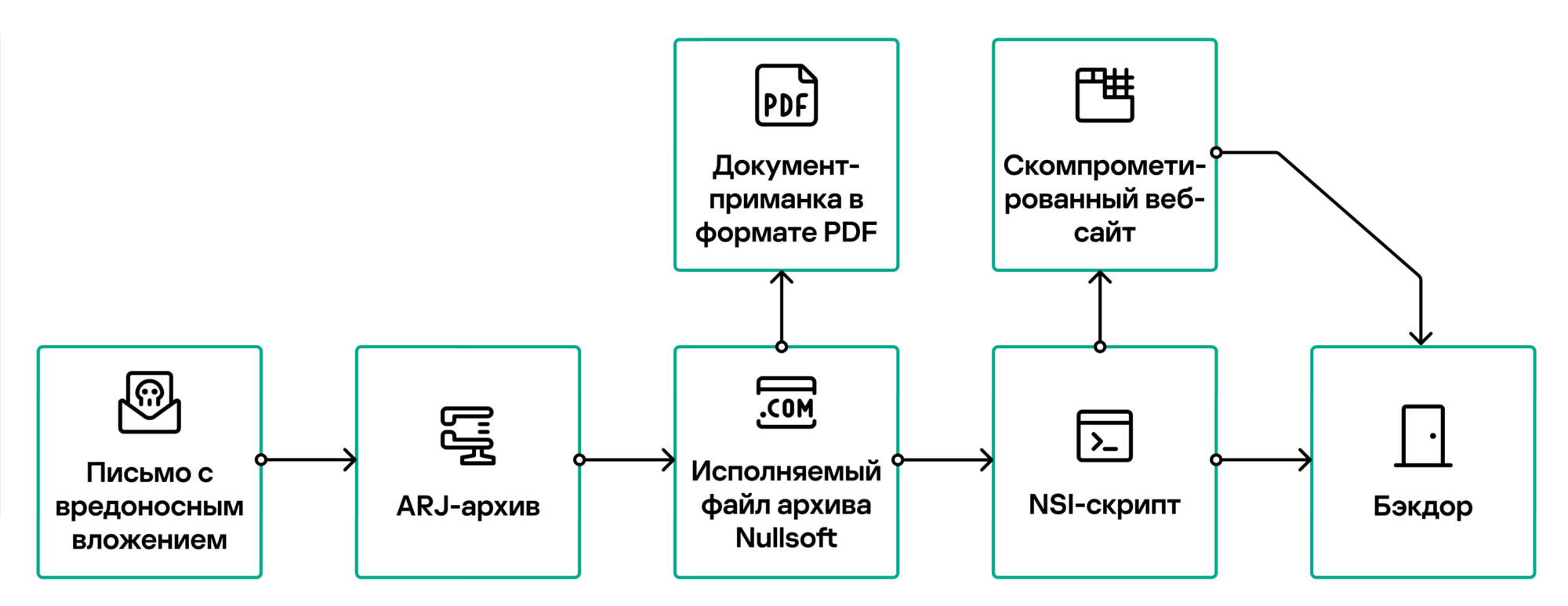
Распространяемые вредоносные вложения (finansovyy_kontrol_2023_180529.rar и detali_dogovora_no_2023_000849.rar) представляли собой ARJ-архив, содержащий исполняемый файл Nullsoft с полезной нагрузкой — маскировочным PDF-документом и скриптом NSIS.
Последний при запуске открывает документ-приманку и вызывает функцию get плагина INetC установщика Nullsoft, которая пытается загрузить в систему вредоносный файл с внешнего ресурса. В случае успеха зловред копируется в папку C:\ProgramData\Microsoft\DeviceSync\ под именем UsrRunVGA.exe, а затем запускается на исполнение со скрытым окном. Чтобы обеспечить ему автозапуск, в системе создается новый ярлык (файл .lnk).
Кроме UsrRunVGA, в рамках данной вредоносной рассылки распространялись еще два бэкдора — Netrunner и Dmcserv, с другим C2-сервером.
Согласно результатам анализа, вредонос UsrRunVGA написан на Go; строки кода зашифрованы простым XOR. После запуска троян проверяет доступ в интернет, подключаясь к сайтам зарубежных СМИ (отправляет HTTP-запросы GET до тех пор, пока все они не вернут код состояния 200 — «ОК»).
При этом используется следующий User-Agent:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.5.
После получения нужных ответов зловред обращается к C2-серверу по HTTPS, вновь ожидая в ответ код 200. Установив соединение, UsrRunVGA проводит ряд проверок на наличие виртуальной среды или песочниц; при обнаружении таких препятствий дальнейшее исполнение прекращается.
Основные функции бэкдора обеспечивают сбор и отправку на C2-сервер информации о зараженной машине (модель и производитель системного диска), а также выполнение команд list (перечислить файлы и папки в указанной директории) или file (передать файл на C2).
Выявлены дополнительные модули UsrRunVGA, выполняемые в отдельных потоках; они придаются зловреду для выполнения следующих задач.
- получение содержимого буфера обмена;
- снятие снимков экрана;
- отправка файлов с указанными расширениями (из папок пользователей) на C2.
Данные, которые бэкдор отправляет на свой сервер, шифруются по AES256-GCM (ключ вшит в код вредоноса).
Обнаруженную в августе новую версию UsrRunVGA отличают отсутствие проверки интернет-доступа, расширенный набор проверок рабочей среды и дополнительный инструмент для кражи паролей из браузеров (список на три десятка позиций, в том числе Яндекс Браузер).
Изменился метод запроса, используемого для передачи системной информации на C2-сервер: теперь это HTTP POST. Содержимое подаваемых команд list / file и параметров стало шифроваться по RSA (ключ для расшифровки вшит в код зловреда).
Авторы UsrRunVGA также заменили AES-ключ, который используется для шифрования данных, отправляемых на командный сервер. Цепочка заражения и вредоносный скрипт-загрузчик остались без изменений.

















