













Вокруг российского мессенджера МАКС разгорелась новая дискуссия о безопасности. Пользователь Хабра под ником sansmaster рассказал, что для входа в веб-версию сервиса можно обойтись без пароля, СМС-кода и даже QR-аутентификации.
Правда, речь идёт не о взломе и не об уязвимости в классическом понимании.
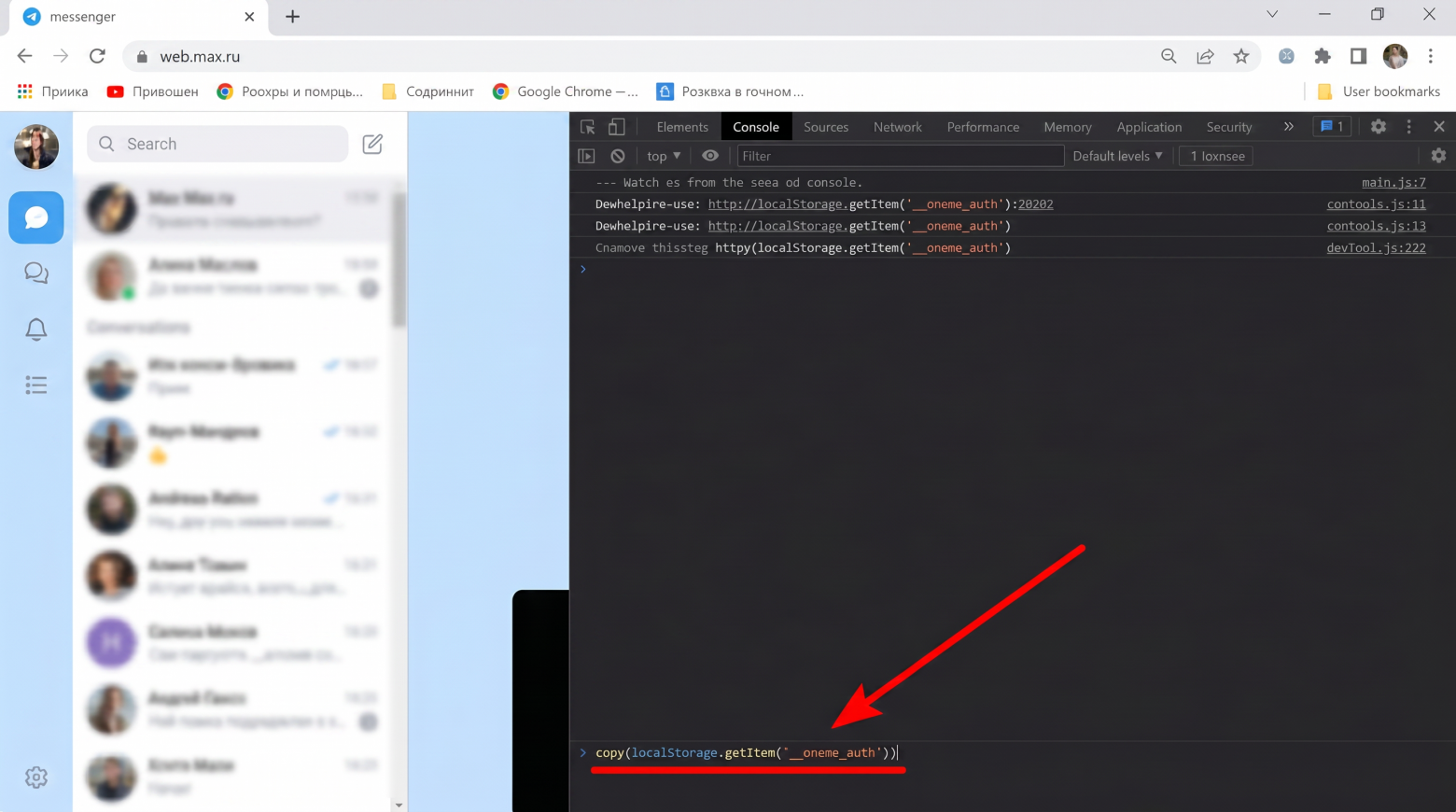
Автор публикации обратил внимание, что после успешного входа в web.max.ru браузер сохраняет токен сессии в локальном хранилище (localStorage). Этот токен позволяет серверу идентифицировать пользователя и поддерживать активную сессию.
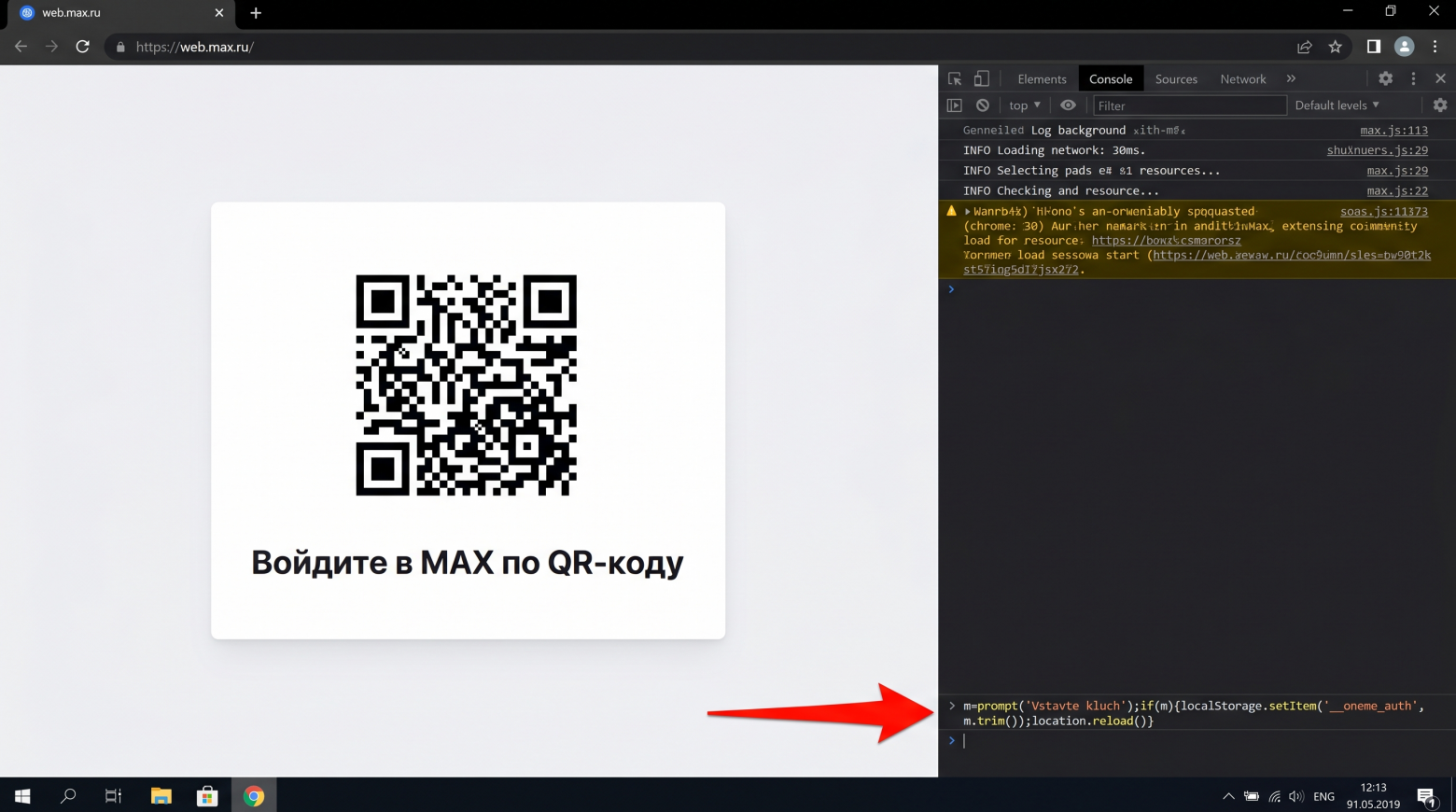
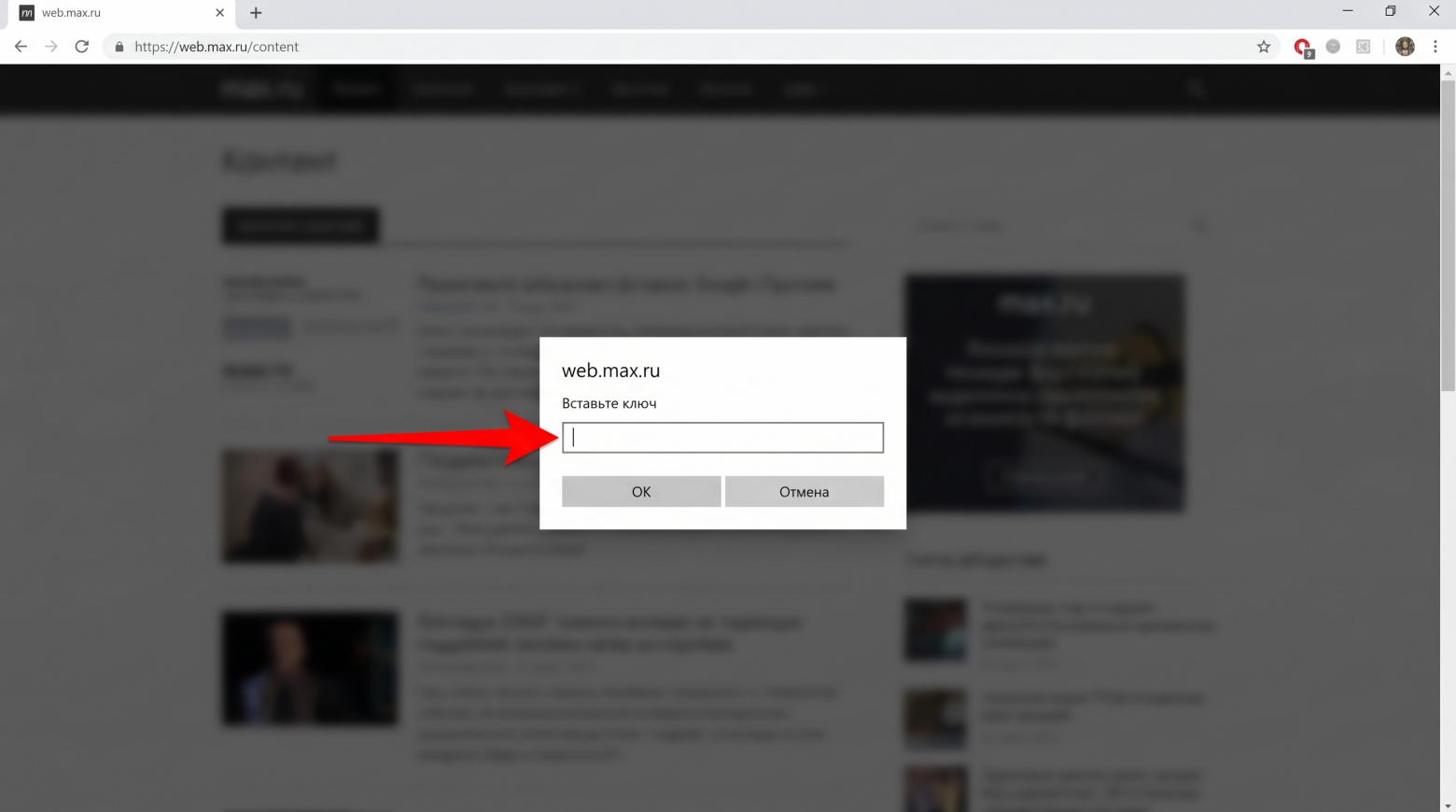
Через консоль разработчика браузера пользователь может извлечь сохранённый токен, а затем импортировать его в другой браузер или на другой компьютер. После перезагрузки страницы веб-версия МАКС откроется уже под нужной учётной записью, и всё это без ввода пароля, получения СМС или сканирования QR-кода.
По сути, речь идёт о переносе уже существующей сессии между браузерами. Сам автор подчёркивает, что никаких эксплойтов или обходов защиты здесь нет. Используются штатные механизмы браузера и данные, которые приложение само сохраняет на устройстве пользователя. Аналогичные принципы работы применяются и во многих других веб-сервисах.
Тем не менее публикация вызвала бурное обсуждение. Многие пользователи удивились тому, насколько легко можно получить доступ к токену через DevTools и перенести его в другую среду.
При этом есть важный нюанс. Для выполнения всей процедуры злоумышленнику уже необходим доступ к устройству или браузеру пользователя, где активна сессия МАКС. Без этого получить токен не получится.
Кроме того, выход из аккаунта или завершение сессии через настройки делает токен недействительным сразу на всех устройствах, где он использовался.
Фактически история стала ещё одним напоминанием о том, что токен аутентификации зачастую представляет не меньшую ценность, чем пароль. Если он попадает в чужие руки, то может открыть доступ к аккаунту без каких-либо дополнительных проверок.



