В университете Флориды изучили достижения артикуляционной фонетики и разработали новую технику распознавания дипфейк-аудио — по отсутствию ограничений, влияющих на работу голосового аппарата человека. Созданный в ходе исследования детектор способен по одной фразе определить подмену с точностью 92,4%.
Создание дипфейков стало возможным лишь с развитием технологий машинного обучения. Новый инструментарий, позволяющий создавать убедительные имитации, уже по достоинству оценили злоумышленники: собрав ПДн из открытых источников, они проводят пробные атаки, в том числе для получения финансовой выгоды.
Инциденты с использованием дипфейков снижают доверие к цифровым средствам коммуникации, но пока редки. Тем не менее, новую угрозу нельзя сбрасывать со счетов, и эксперты озаботились совершенствованием средств подтверждения личности.
Выявить поддельное видео, созданное с помощью ИИ, можно путем анализа визуальных артефактов — по разнице в мимике (частоте моргания, например) или различию приметных частей лица (подбородка, бровей, скул, усов и бороды, веснушек, родимых пятен). Качественный синтез речи, используемый с неблаговидной целью, представляет более серьезную угрозу, так как дистанционное общение зачастую происходит только вербально — по телефону, с использованием радиосвязи или аудиозаписи.
Защититься от таких высокотехнологичных атак, по мнению ученых из Флориды, можно с помощью газодинамики — оценкой речевого тракта говорящего, который можно воссоздать средствами моделирования. Дело в том, что на человеческую речь влияют анатомические особенности его голосового аппарата: связок, языка, челюстей, губ. При генерации звуков (фонем) эти участники процесса используются по-разному, но всегда в пределах лимитов, заданных природой.
Исследование показало, что звуковые дипфейки не учитывают такие ограничения. Более того, при реконструкции речевого тракта они показали схожие результаты, далекие от реальности:
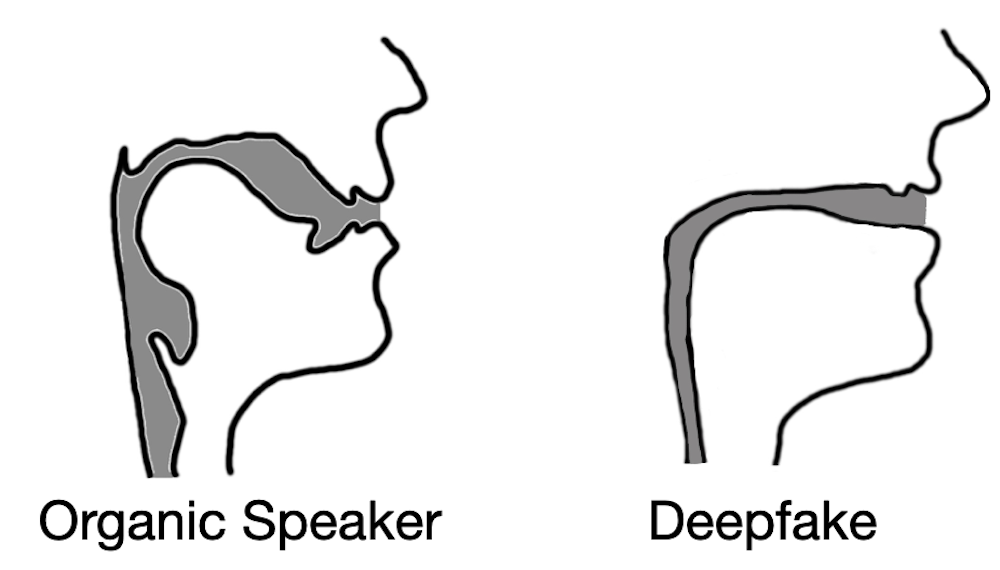
Способность современного противника ответить на этот вызов университетские исследователи оценили как близкую к нулю. О своем методе выявления дипфейк-аудио они рассказали (PDF) в прошлом месяце на конференции USENIX по безопасности, которая прошла в Бостоне. Созданный в ходе исследования программный код выложен в общий доступ на GitHub.

















