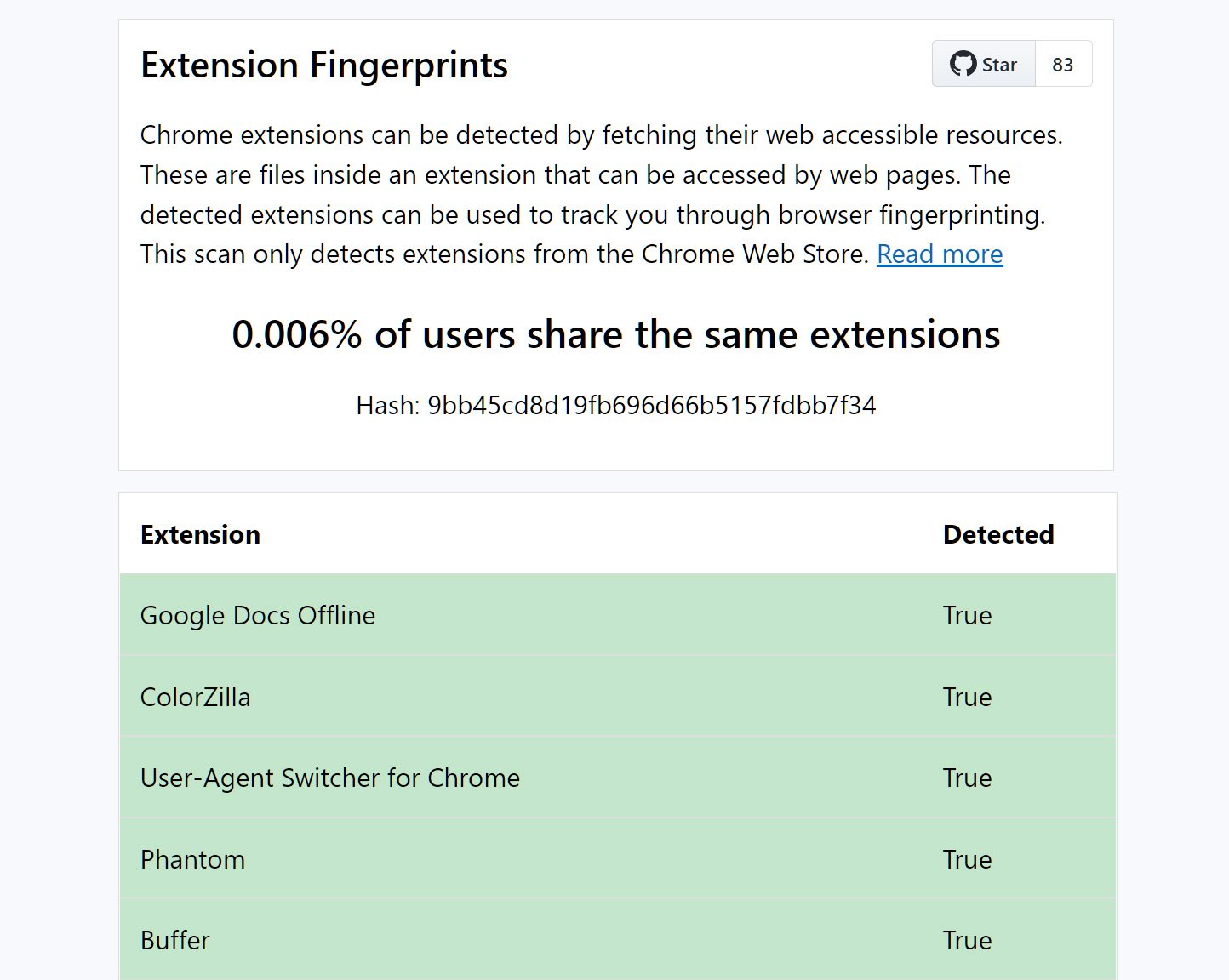
Исследователь в качестве эксперимента создал веб-сайт, использующий установленные у посетителей расширения браузера Google Chrome для снятия его цифрового отпечатка и последующей идентификации и отслеживания этого пользователя.
Цифровой отпечаток, как правило, подразумевает использование различных характеристик устройства пользователя, которые помогают веб-сервисам «узнавать» посетителя. Среди таких характеристик могут быть инсталлированные приложения, мощность GPU, разрешение экрана, аппаратная начинка и даже установленные шрифты.
На выходных веб-разработчик, известный под онлайн-псевдонимом “z0ccc“, поделился своим методом снятия цифрового отпечатка — “Extension Fingerprints“. Суть заключается в том, что создать трекинг-хеш можно с помощью установленных аддонов Google Chrome.
Известно, что при создании Chrome-расширения можно отметить определённые активы в качестве “доступных из Сети ресурсов“, к которым могут получить доступ веб-страницы и другие аддоны.
Как правило, такие ресурсы представляют собой файлы изображений, у которых указано свойство “web_accessible_resources“. Например, это может выглядеть так:
"web_accessible_resources": [
{
"resources": [ "logo.png" ],
"matches": [ "https://anti-malware.ru/*" ]
}
],
Всё это можно использовать для проверки установленных в системе пользователя расширений Google Chrome. Выделив инсталлированные аддоны, условный злоумышленник может создать цифровой отпечаток браузера посетителя.
«Фетчинг определённых защищённых расширений занимает дольше времени, чем неустановленных аддонов. Замеряя временные промежутки, вы можете вычислить, какие расширения пользователь установил», — объясняет “z0ccc“ на GitHub-странице своего проекта.