








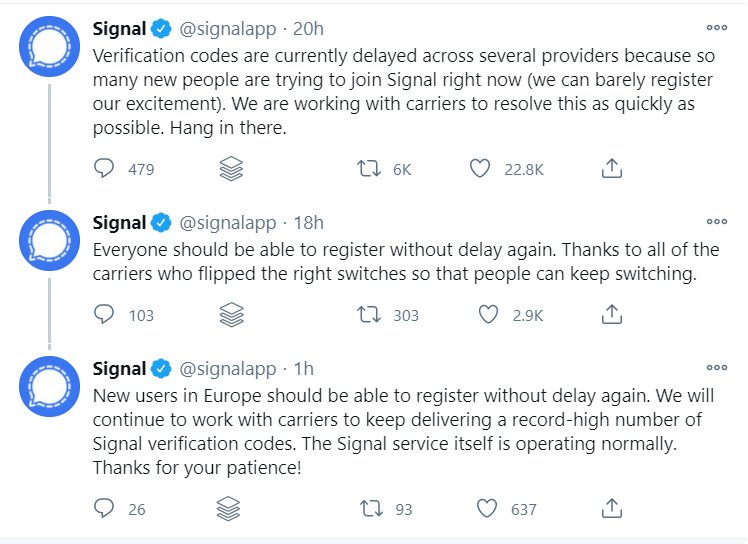
Сервис обмена мгновенными сообщениями Signal, в котором сделан упор на конфиденциальность и безопасность, столкнулся с невиданной ранее нагрузкой из-за массовой миграции пользователей с WhatsApp. По словам разработчиков мессенджера, сейчас им удалось решить проблему с задержкой в процессе верификации.
Если пользователю нужно настроить Signal в первый раз, потребуется ввести и подтвердить телефонный номер с помощью специальных кодов верификации. Из-за повышенной нагрузки в связи с уходом людей с WhatsApp в приложении Signal наблюдалась задержка верификации.
Официальный Twitter-аккаунт мессенджера посвятил проблеме целую ветку, уточнив уже спустя пару часов, что доставка кодов верификации восстановлена, а сервис теперь функционирует в прежнем режиме.
Забавно, что проблемы в работе Signal вызвал другой мессенджер — WhatsApp, а точнее новая политика системы обмена текстовыми сообщениями. Напомним, что на днях стало известно об изменениях правил WhatsApp, касающихся передачи пользовательских данных и плотной интеграции между продуктами Facebook.
Согласно новой политике, с 8 февраля 2021 года владельцы мессенджера смогут деактивировать ваш аккаунт, если вы не согласитесь на передачу данных Facebook. Среди подобных сведений могут значиться: указанная при регистрации аккаунта информация, телефонные номера, детали транзакций, взаимодействие с платформой, данные о мобильном устройстве, IP-адрес и т. п.






