














Microsoft тестирует для Windows 11 новую функцию Copilot под названием PC Insights. Суть будет в следующем: пользователь спрашивает, что происходит с компьютером, а ИИ смотрит на загрузку процессора, оперативной памяти, видеокарты, состояние накопителей и подключенных устройств.
Copilot сможет отвечать на вопросы вроде: «Сколько у меня свободного места?», «Потянет ли компьютер игру на 100 Гбайт?», «Какая у меня видеокарта?», «Работает ли антивирус?» и «Почему система тормозит?».
Для этого он получит доступ к системным данным Windows, включая сведения о CPU, RAM, GPU, BIOS, батарее, Wi-Fi, Bluetooth, USB-устройствах, принтерах и веб-камерах.
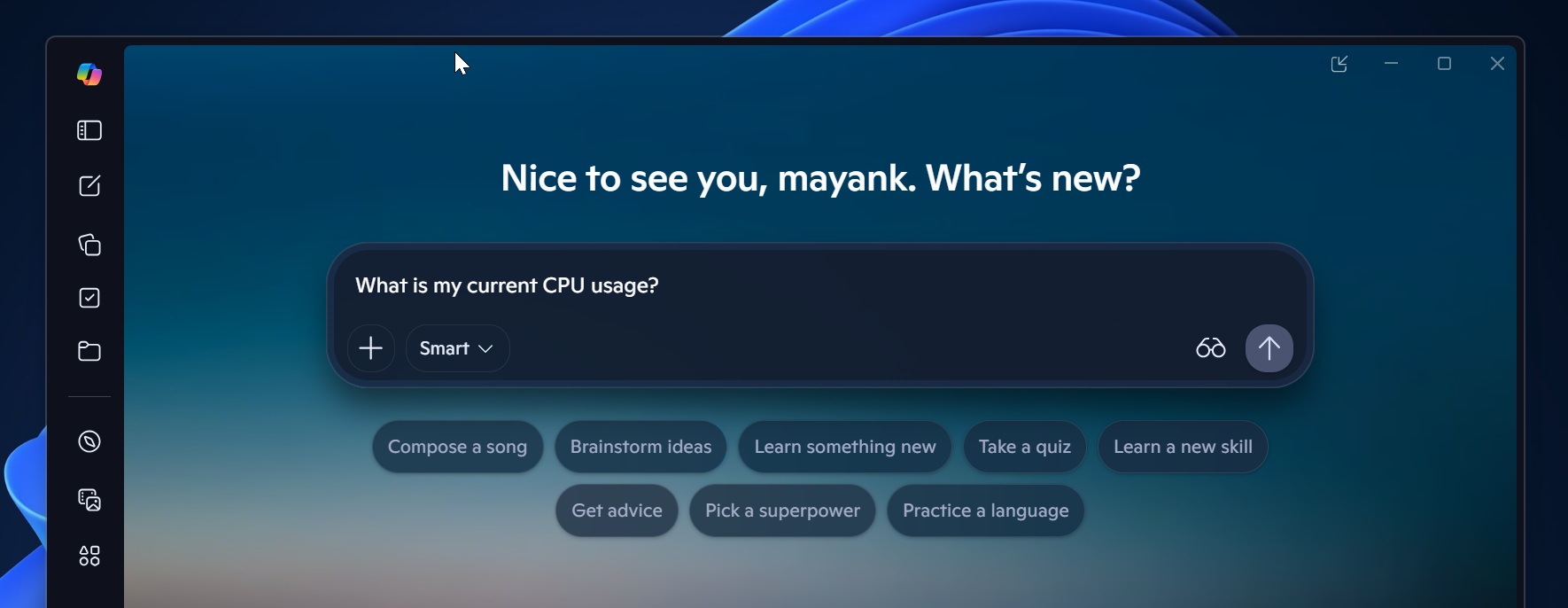
В Microsoft уверяют, что функция будет добровольной. Перед доступом к данным Copilot должен запросить разрешение. Можно выбрать режим «спрашивать каждый раз» или разрешить постоянный доступ.
При этом исправлять проблемы ИИ пока не сможет — только читать показатели и объяснять, что пошло не так. Личные файлы и системные сведения, по версии Microsoft, не будут использоваться для обучения моделей. А вот запросы и ответы могут пойти на улучшение Copilot (в зависимости от настроек).
Главная ирония в другом. Copilot собираются использовать для поиска пожирателей ресурсов, но он сам оказался весьма прожорливым. После запуска приложение может занимать около 800 Мбайт, а иногда и почти 1 Гбайт оперативной памяти, даже когда ничего не делает.
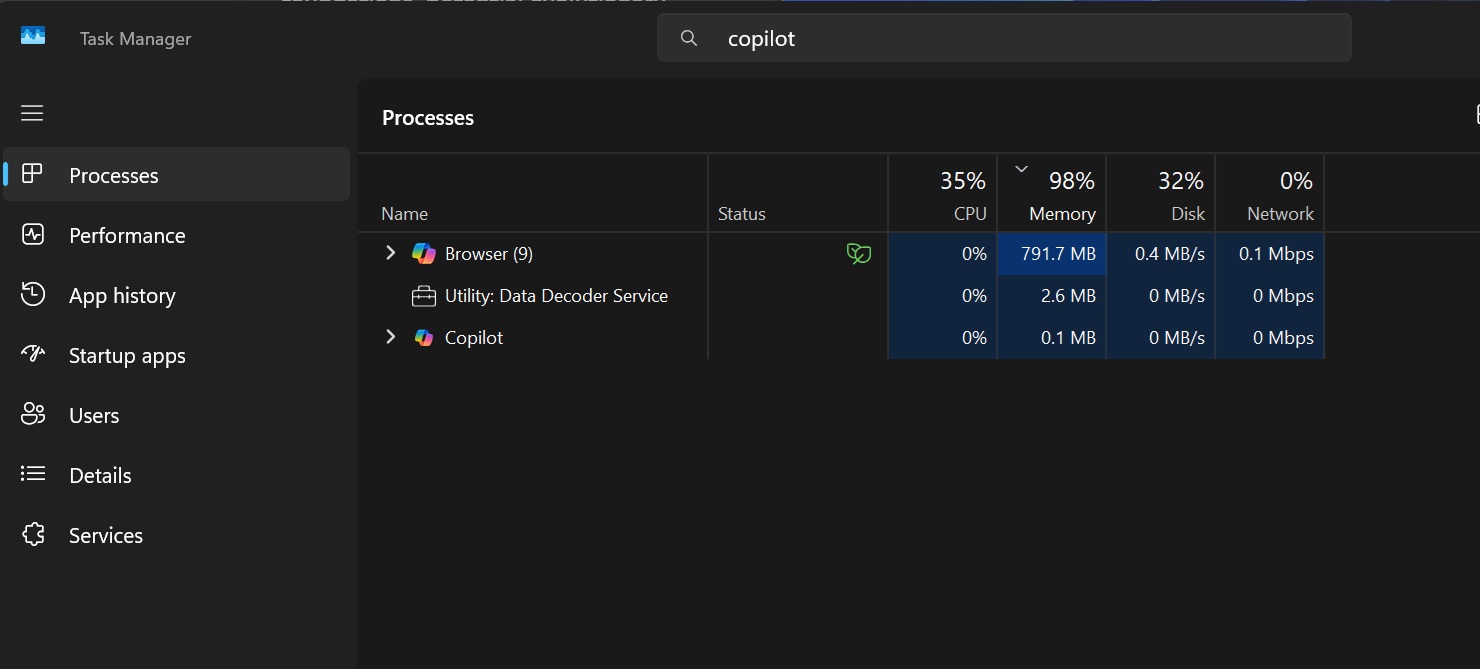
Причина — очередная перестройка сервиса. Copilot снова превратили в веб-приложение и упаковали вместе с отдельной копией Microsoft Edge. В диспетчере задач он теперь даже может отображаться как браузер.



