














У российских пользователей возникли проблемы сразу с несколькими популярными зарубежными сервисами. 23 июня появились многочисленные сообщения о том, что без VPN перестали нормально работать Twitch, Discord и PUBG: Battlegrounds.
Наибольшее количество жалоб связано с Twitch. Интересно, что сам сайт видеоплатформы открывается без проблем: пользователи могут заходить на страницы каналов, читать и отправлять сообщения в чат. Однако при попытке запустить трансляцию возникают сложности.
По словам пользователей, вместо стрима отображается ошибка 2000. Обычно она свидетельствует о проблемах со связью между видеоплеером и серверами Twitch. В результате трансляции либо вообще не запускаются, либо зависают сразу после открытия.
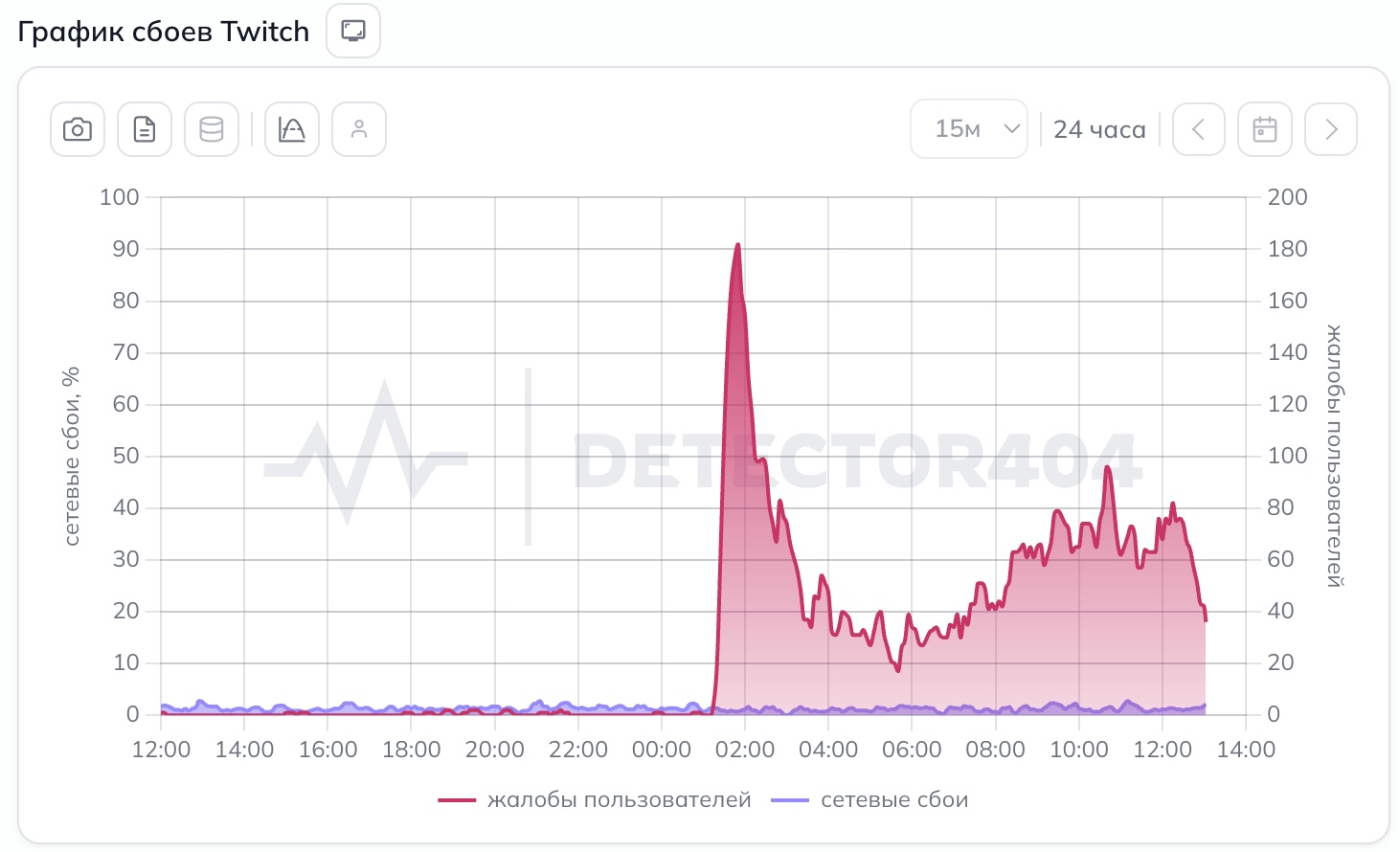
Кроме того, некоторые пользователи сообщают о трудностях при переходе между разделами платформы. В отдельных случаях Twitch может частично или полностью не отвечать на запросы.
Параллельно поступают жалобы на работу Discord и PUBG: Battlegrounds. По словам пользователей, подключиться к сервисам без использования средств обхода ограничений не получается.
При этом официальных подтверждений масштабного сбоя со стороны Twitch пока нет. Согласно данным страницы статуса сервиса, все основные системы платформы работают в штатном режиме и никаких аварий не зафиксировано.
Из-за этого пока остается неясным, связаны ли проблемы с инфраструктурой самих сервисов, особенностями маршрутизации трафика или иными причинами на стороне российских пользователей и операторов связи.
Пока пользователи активно обсуждают ситуацию в соцсетях и на профильных площадках, многие отмечают, что доступ к сервисам восстанавливается после подключения VPN или других средств обхода.



