







Несмотря на то, что версия Firefox 65 вышла буквально на днях, в Сети появилась информация о новых функциях, которые Mozilla планирует реализовать в Firefox 67. Согласно этим данным, компания сделает еще больший акцент на обеспечении безопасности своих пользователей.
Согласно информации на официальном сайте, которой поделились пользователи проекта Bugzilla, в Firefox 67 будет реализована защита от вредоносных криптомайнеров, а также от различных скриптов, предназначенных для фингерпринтинга (снятия цифрового отпечатка пальца).
Принцип работы и дизайн новых функций можно увидеть на соответствующем скриншоте:
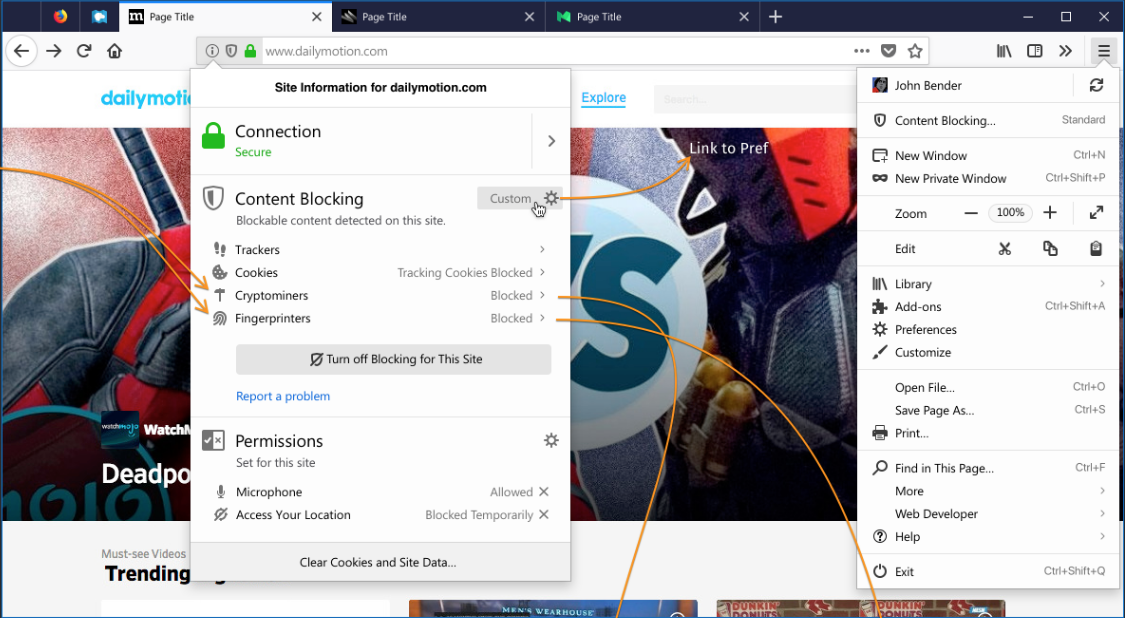
На данный момент дата релиза Firefox 67 назначена на 14 мая 2019 года.
Напомним, что выпущенный на прошлой неделе Firefox 65 уже успел отметиться наличием проблем — пользователи пожаловались на вывод предупреждения «Ваше соединение незащищенно» при посещении популярных сайтов. Mozilla была вынуждена приостановить рассылку обновлений для систем Windows.
Опытным путем пользователи выяснили, что проблемы с Firefox 65 испытывают те, у кого установлены антивирусы AVG или Avast. Надоедливое сообщение выводилось при посещении сайтов, работающих по HTTPS.






