















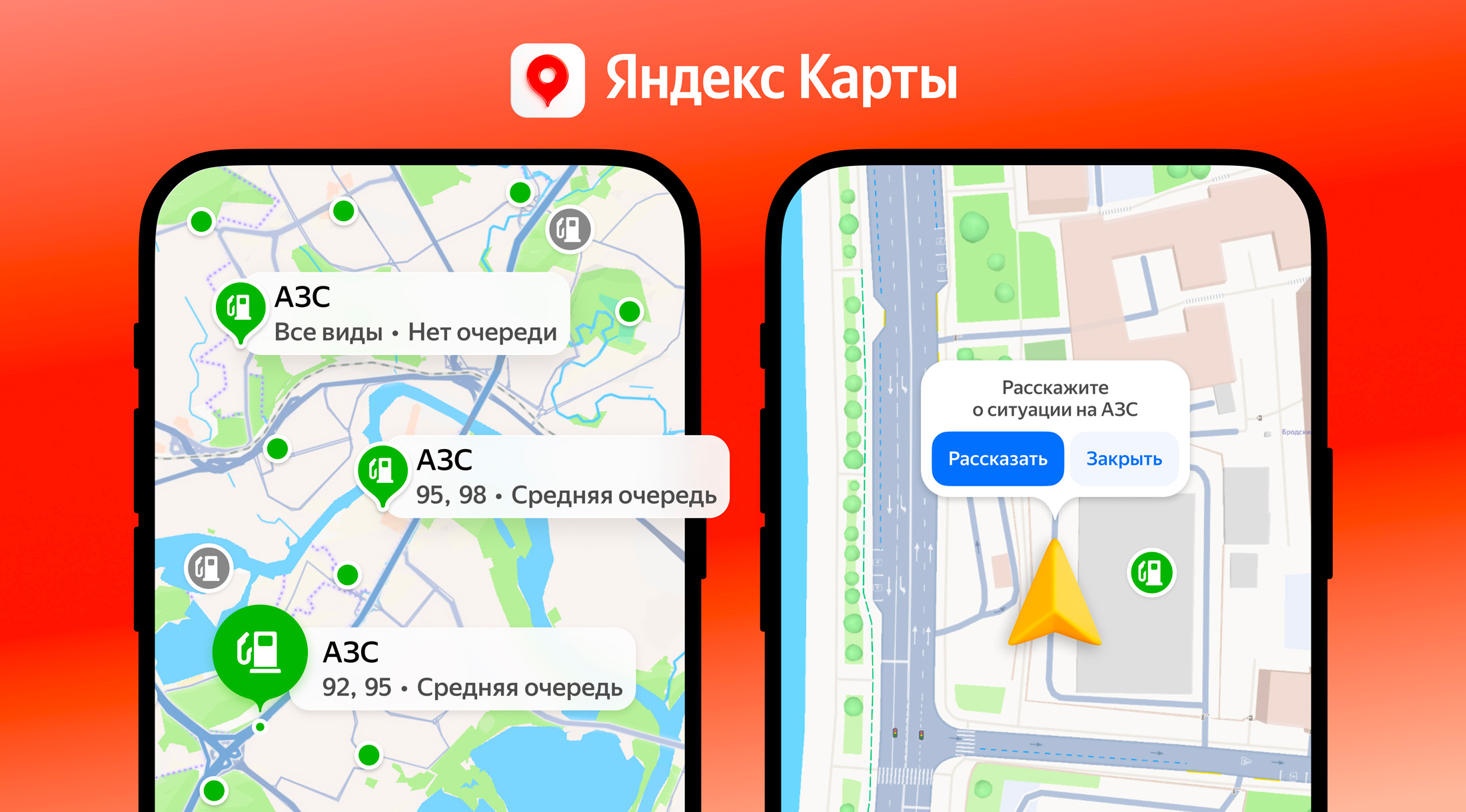
Яндекс обновил сервисы для водителей: теперь Карты и Навигатор показывают, есть ли на конкретной АЗС топливо и насколько велика очередь. Всё это видно прямо в карточке заправки, там же можно сразу построить маршрут.
Данные об очередях появились и в «Яндекс Go» с «Заправками». Функция уже работает в Москве, Санкт-Петербурге и ещё 14 крупных городах, включая Казань, Екатеринбург, Краснодар, Новосибирск, Самару и Челябинск.
Информацию собирают сразу из нескольких источников. Яндекс анализирует обезличенные данные о заказах топлива, сведения от таксистов в «Яндекс Про» и дорожную ситуацию рядом с АЗС. Плюс подключили самих водителей: тем, кто заправился или просто проехал мимо станции, могут предложить короткий опрос.
Ещё одно нововведение — экономичные маршруты. Карты и Навигатор теперь могут предложить путь, на котором машина потратит меньше топлива. Он не обязательно будет самым быстрым, зато может оказаться выгоднее за счёт более плавной скорости и меньшего числа светофоров.
Получается, маршрут теперь можно выбирать не только по принципу «где быстрее», но и «где не сжечь полбака и не провести вечер в очереди».
Пока функция доступна только там, где Яндекс получает достаточно регулярных и достоверных данных. В остальных городах её обещают включать по мере накопления информации.



