







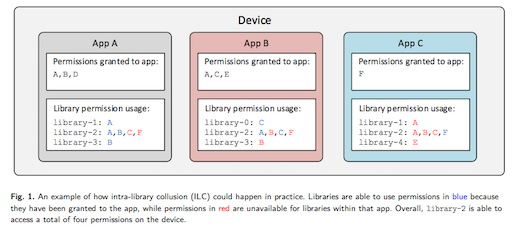







Доверять ИИ написание кода — удобно. Но, как выяснили исследователи из Mozilla Zero Day Investigative Network (0DIN), иногда ИИ может стать идеальным помощником для киберпреступников. Эксперты продемонстрировали новую технику атаки на разработчиков, использующих ИИ-ассистентов вроде Claude Code.
Вся схема строится вокруг обычного на вид GitHub-репозитория, в котором нет ни вредоносного кода, ни подозрительных команд, ни других очевидных признаков компрометации.
Вместо этого злоумышленники используют привычное желание ИИ починить проект. В репозитории размещается Python-пакет, который при запуске специально выдает ошибку и предлагает выполнить команду инициализации.
Для разработчика это выглядит как типичная проблема при первом запуске проекта. А Claude Code воспринимает сообщение как руководство к действию и автоматически запускает рекомендованную команду, пытаясь исправить ошибку.
Скрипт обращается к DNS TXT-записи, контролируемой злоумышленником, получает оттуда скрытую команду и выполняет ее. Вредоносный код при этом вообще отсутствует в репозитории, он загружается только в момент выполнения.
Такой подход серьезно осложняет обнаружение атаки. Автоматические сканеры и специалисты по безопасности могут не найти ничего подозрительного при анализе проекта, поскольку опасная нагрузка появляется уже после запуска.
Если атака проходит успешно, злоумышленник получает интерактивную оболочку с правами пользователя. Этого достаточно, чтобы похитить API-ключи, токены, переменные окружения, локальные конфигурации и другие секреты разработчика.
В Mozilla предупреждают, что подобные репозитории могут распространяться под видом тестовых заданий при найме, обучающих проектов, статей, блогов или просто через личные сообщения разработчикам.
Исследователи рекомендуют разработчикам внимательно проверять все команды, которые предлагает выполнить ИИ, а создателям агентных помощников — показывать пользователю полную цепочку выполняемых действий, включая код и скрипты, которые подгружаются во время работы.



