Известный исследователь Йоуко Пюннёнен (Jouko Pynnönen) раскрыл в своем блоге детали опасной уязвимости, которую компания Yahoo исправила на прошлой неделе. Интересно, что почти год назад специалист уже находил практически аналогичный баг в веб-интерфейсе почтового сервиса Yahoo.
Тогда компания выплатила Пюннёнену вознаграждение в размере 10 000 долларов, и этот приз стал одним из самых крупных за всю историю существования bug bounty программы Yahoo. Теперь, спустя чуть меньше года, исследователь заработал на очень похожей уязвимости еще 10 000 долларов.
В блоге специалист объясняет, что обнаруженная им проблема позволяла злоумышленнику отправить жертве письмо со встроенным вредоносным кодом. Данный код исполнялся сразу же, как только жертва читала послание. Не требовалось никаких кликов по ссылкам, или открытия подозрительных файлов.
Равно как и год назад, проблема связана с некорректной работой фильтра Yahoo, который должен проверять корреспонденцию на наличие малвари и вредоносного кода. Более того, Пюннёнен искал второй такой же баг специально, хотя и понимал, что вероятность обнаружить еще одну XSS-уязвимость такого рода, крайне мала. Но исследователю улыбнулась удача,
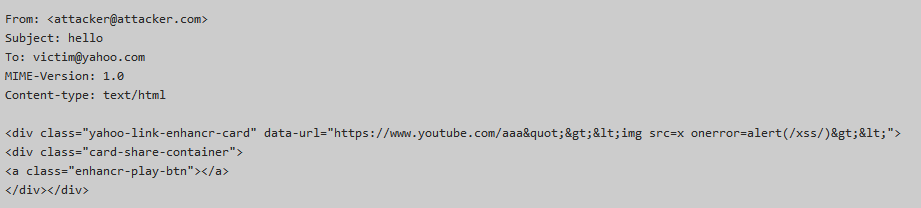
Эксперт пишет, что на этот раз он изучал различные опции, которые обошел вниманием в прошлый раз, к примеру, функцию «Поделиться файлами с облачного хостинга». Пюннёнен заметил, что в данном случае к письму прикладывается не обычное вложение, но HTML-ссылка на Google Docs или Dropbox. Выглядит это так:
Специалист не мог не обратить внимания на атрибуты data-* HTML, и быстро понял, что в прошлом году ему удалось вычислить далеко не все атрибуты, которые можно протащить сквозь фильтр Yahoo. К тому же атрибуты data-* HTML используются для хранения специфических данных приложений и типичны для JavaScript. Так Пюннёнен обнаружил новый вектор атаки.
Вскоре исследователь разработал тестовый кейс следующего вида:
При просмотре такого сообщения в Yahoo Mail, замаскированный JavaScript немедленно выполняется (см. верхнюю иллюстрацию). Пюннёнен отследил проблему до одной из функций почтового сервиса: t.shareMenu.generateButton(r.cardUrl,s), которую эксперт приводит в блоге в слегка обфусцированном виде:
В итоге Пюннёнен создал proof-of-concept, который отправил специалистам Yahoo, вместе с информацией о проблеме. PoC исследователя использует AJAX, и как только жертва открывает вредоносное письмо, эксплоит считывает все содержимое папки «Входящие» и отправляет его на сервер атакующего. Кроме того, новая брешь позволяет оснастить письмо саморазмножающимся червем, который будет внедряться в подпись каждого исходящего письма жертвы, заражая все новые и новые ящики.
12 ноября 2016 года Пюннёнен передал свои изыскания сотрудникам Yahoo через официальную программу bug bounty на HackerOne. Уязвимость была устранена 29 ноября 2016 года, а исследователю вновь заплатили 10 000 долларов. Пюннёнен пишет, что хотя уязвимость легко эксплуатировать, найти ее оказалось не так уж просто. «Не сказал бы, что это примитивный баг, подобное вряд ли можно обнаружить, используя автоматические инструменты и сканеры», — говорит эксперт.
Банк России взялся за год создать единый реестр платежных карт с тем, чтобы облегчить кредитно-финансовым организациям соблюдение планируемых к вводу лимитов: до 20 карт у гражданина, до пяти в одном банке.
О намерении ЦБ запустить в будущем году такой справочник для отрасли стало известно из выступления в Думе замглавы Минцифры Ивана Лебедева. С его слов, оба регулятора вместе прорабатывали этот вопрос.
«Вы знаете, что это ограничение по банкам — по картам, — цитирует РИА Новости спикера. — Центральный банк взял на себя обязательство в течение года подготовить базу единую по всей стране, из которой будет видно, сколько у каждого гражданина в каком банке оформлено карт.
Свидетельство о регистрации СМИ ЭЛ № ФС 77 - 68398, выдано федеральной службой по надзору в сфере связи, информационных технологий и массовых коммуникаций (Роскомнадзор) 27.01.2017 Разрешается частичное использование материалов на других сайтах при наличии ссылки на источник. Использование материалов сайта с полной копией оригинала допускается только с письменного разрешения администрации.