














Компания «Эфшесть/F6» обнаружила новый сценарий мошенников: злоумышленники от имени популярных автоблогеров и автомобильных сообществ продают билеты на несуществующие шоу с распаковкой контейнеров, внутри которых якобы находятся автомобили. Пользователям предлагают купить билет на съёмки видео и лично открыть один из контейнеров.
По легенде мошенников, в каждом контейнере стоит автомобиль стоимостью не менее 75 тыс. рублей, а билет даёт право забрать машину себе. Цена участия — от 5 тыс. до 35 тыс. рублей.
В «Эфшесть/F6» объясняют, что новая схема выросла из популярности видеороликов, где автоблогеры действительно вскрывают контейнеры с неизвестным содержимым. Мошенники просто взяли узнаваемый формат, добавили к нему имена известных блогеров и превратили всё это в фейковый розыгрыш.
На самом деле блогеры такие мероприятия не проводят и платный доступ к распаковке не продают. Сам формат используется для создания видеоконтента, а не для розыгрышей с участием зрителей. Некоторые автоблогеры уже предупредили подписчиков в соцсетях, что не имеют отношения к подобным предложениям.
Изначально схема распространялась в Telegram. Злоумышленники добавляли пользователей, интересующихся автомобильной тематикой, в фейковые группы, которые имитировали официальные сообщества блогеров. Затем жертве писал якобы менеджер автоблогера и предлагал поучаствовать в розыгрыше.
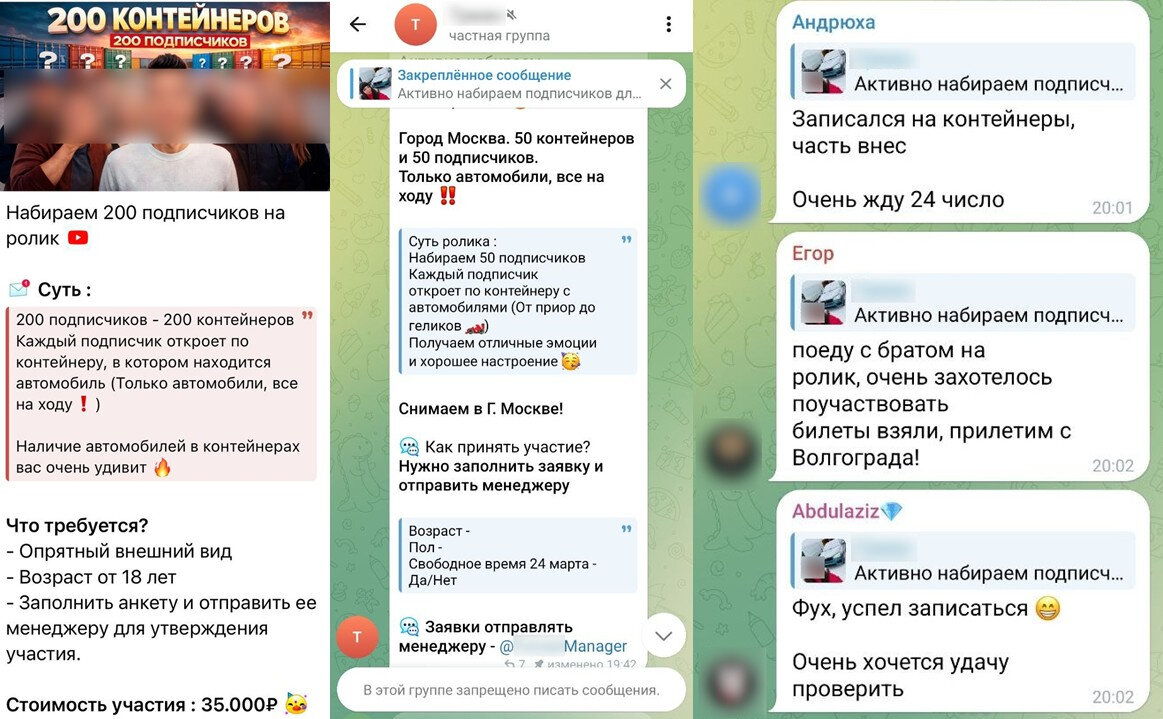
Внутри таких групп мошенники создавали видимость активности: публиковали сообщения, ссылки, подробности о месте проведения и условиях участия. Всё это должно было создать ощущение срочности и подтолкнуть человека быстрее купить билет.
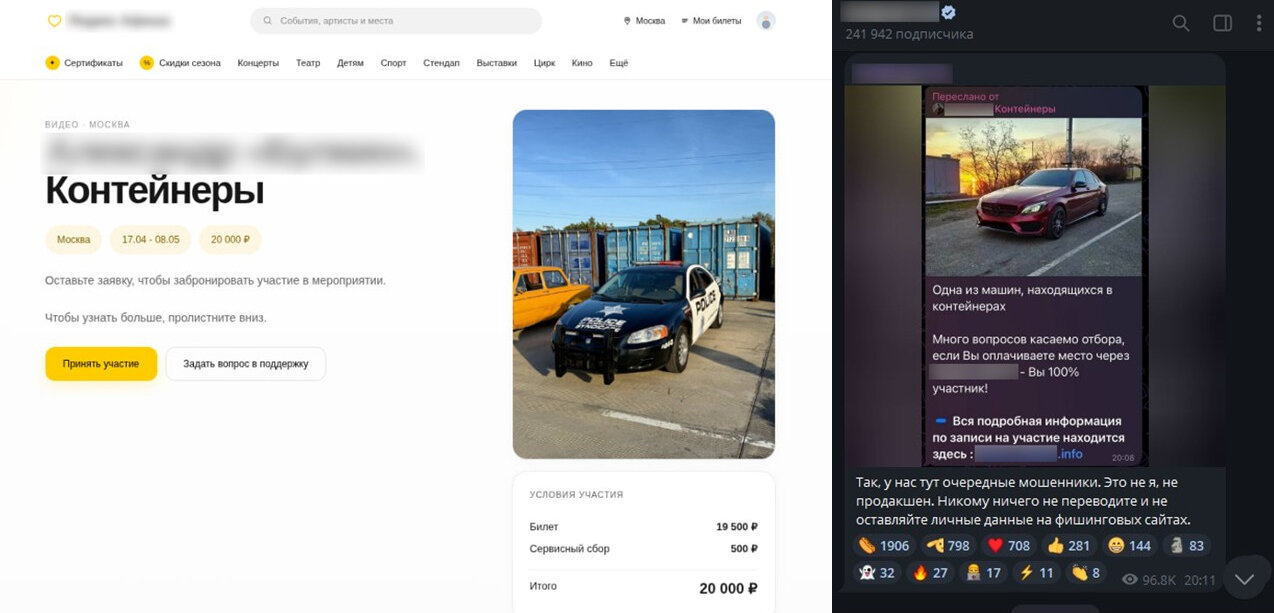
Для оплаты пользователя переводили на другого менеджера, который отправлял реквизиты — номер телефона или данные банковского счёта. В «Эфшесть/F6» отметили, что в рамках схемы использовались реквизиты одного и того же дропа, а банк и мобильный номер были связаны с Таджикистаном.
Позже злоумышленники усложнили сценарий и начали создавать сайты-двойники популярных российских билетных сервисов. Там размещалась информация о вымышленных мероприятиях, а на странице покупки билета снова появлялись реквизиты для перевода денег.
По словам Алексея Литвинова, аналитика второй линии CERT департамента Digital Risk Protection F6, все известные компании мошеннические ресурсы, связанные с этой схемой, уже заблокированы. Профили и сообщества в Telegram, через которые распространялись фейковые розыгрыши, также заблокированы или помечены как мошеннические.
Специалисты советуют не доверять предложениям о закрытых розыгрышах от имени блогеров, особенно если участие нужно оплачивать переводом на карту или по номеру телефона. Лучше проверять такие акции только через официальные каналы авторов и не переходить по ссылкам из сомнительных групп.



