











Apple решила заняться одной из самых раздражающих проблем цифровой безопасности — паролями, которые пользователи годами обещают себе сменить, но так и не меняют. На конференции WWDC 2026 компания представила новую функцию Apple Intelligence, которая сможет автоматически обновлять слабые и скомпрометированные пароли.
Сейчас Safari и приложение «Пароли» уже умеют предупреждать о небезопасных комбинациях, дубликатах и утечках. Однако дальше предупреждений дело не заходит, менять пароль приходится вручную.
В iOS 27 ситуация изменится. Apple внедряет агентный подход: система сможет самостоятельно выполнять часть действий от имени пользователя. Если сервис поддерживает автоматическую смену учётных данных, Apple Intelligence сможет заменить слабый пароль на новый сложный вариант практически без участия владельца устройства.
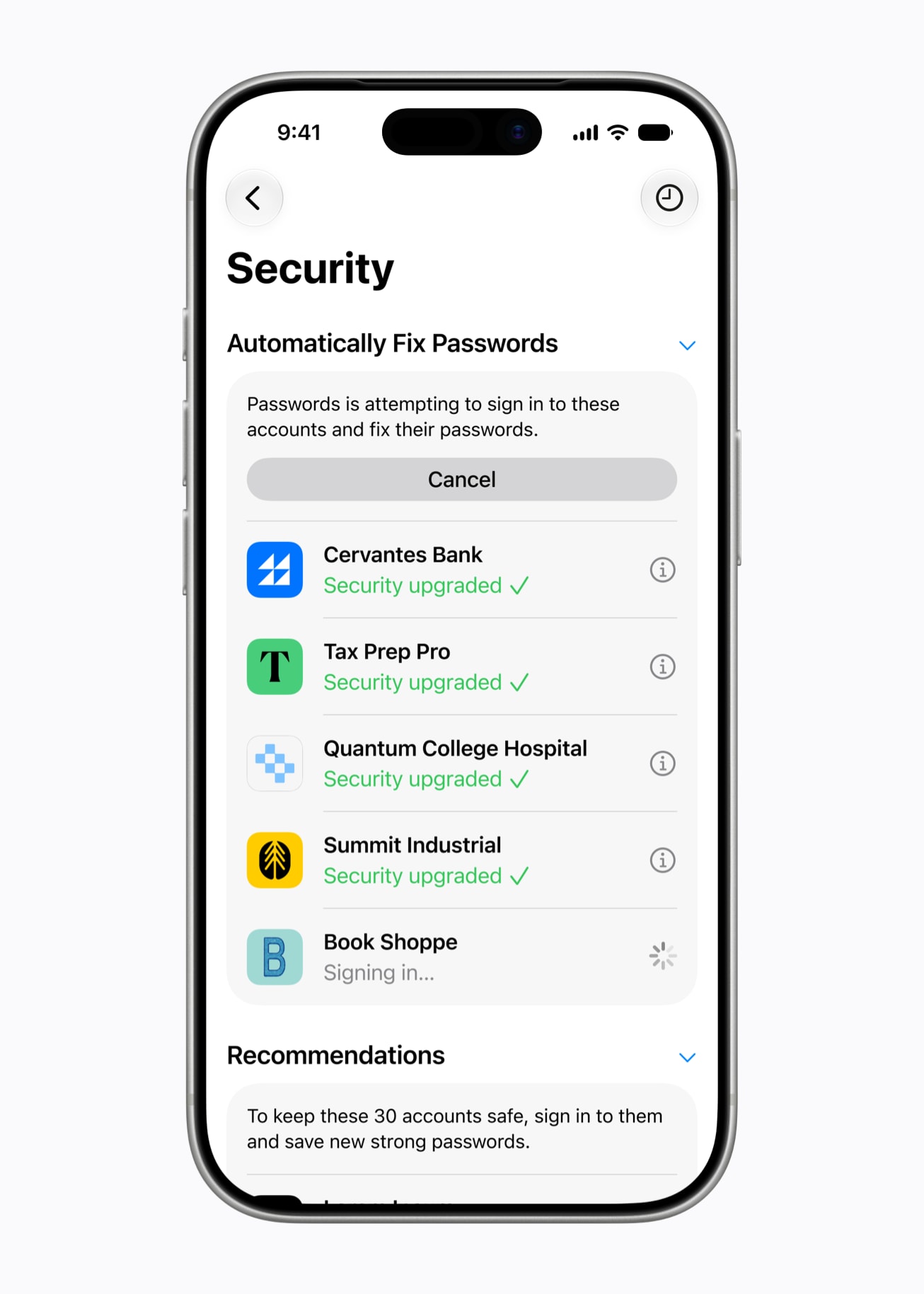
По сути, менеджер паролей превращается из пассивного наблюдателя в активного помощника. Особое внимание Apple традиционно уделяет вопросам конфиденциальности.
В корпорации утверждают, что новые функции работают на базе собственных моделей Apple Foundation Models, а большая часть вычислений выполняется непосредственно на устройстве.
Для более сложных сценариев используется инфраструктура Private Cloud Compute. По словам Apple, при обработке запросов в облаке личные данные пользователей не сохраняются и остаются недоступными как для самой компании, так и для третьих лиц.
Интересно, что при создании своих моделей Apple сотрудничала с Google. В компании сообщили, что использовали технологии Gemini для дообучения собственных ИИ-моделей, которые затем интегрировали в экосистему Apple Intelligence.
Новая система автоматической смены паролей появится вместе с iOS 27 позже в этом году. А самые нетерпеливые уже могут протестировать функцию в бета-версии для участников программы Apple Developer Program.
Похоже, Apple решила, что пользователям больше нельзя доверять даже такую простую задачу, как смена пароля. И, судя по количеству аккаунтов с паролями вроде «123456» и «qwerty», в Купертино могут быть не так уж неправы.



