














Исследователи раскрыли новую группировку Lurking Lizard, которая несколько лет строила бизнес на вредоносных резидентских прокси. Проще говоря, злоумышленники заражали устройства пользователей и превращали их в прокси-узлы, через которые потом можно гонять чужой интернет-трафик.
Владелец устройства при этом мог даже не подозревать, что его домашний IP уже работает на чей-то мутный бизнес.
По данным Infoblox, активность Lurking Lizard прослеживается как минимум с августа 2022 года. Инфраструктура группировки включает более 230 доменов-двойников. Один из свежих примеров — кампания с троянизированным установщиком 7-Zip на домене 7zip[.]com. Пользователь думает, что качает архиватор, а на деле может записать своё устройство в прокси-ботнет.
Группировка не ограничивалась одним брендом. Lurking Lizard имитировала крупные прокси-сервисы, включая IPIDEA, SmartProxy, IP Royal и 911Proxy, а также запускала фейковые независимые сайты с обзорами, чтобы загонять трафик на собственные витрины.
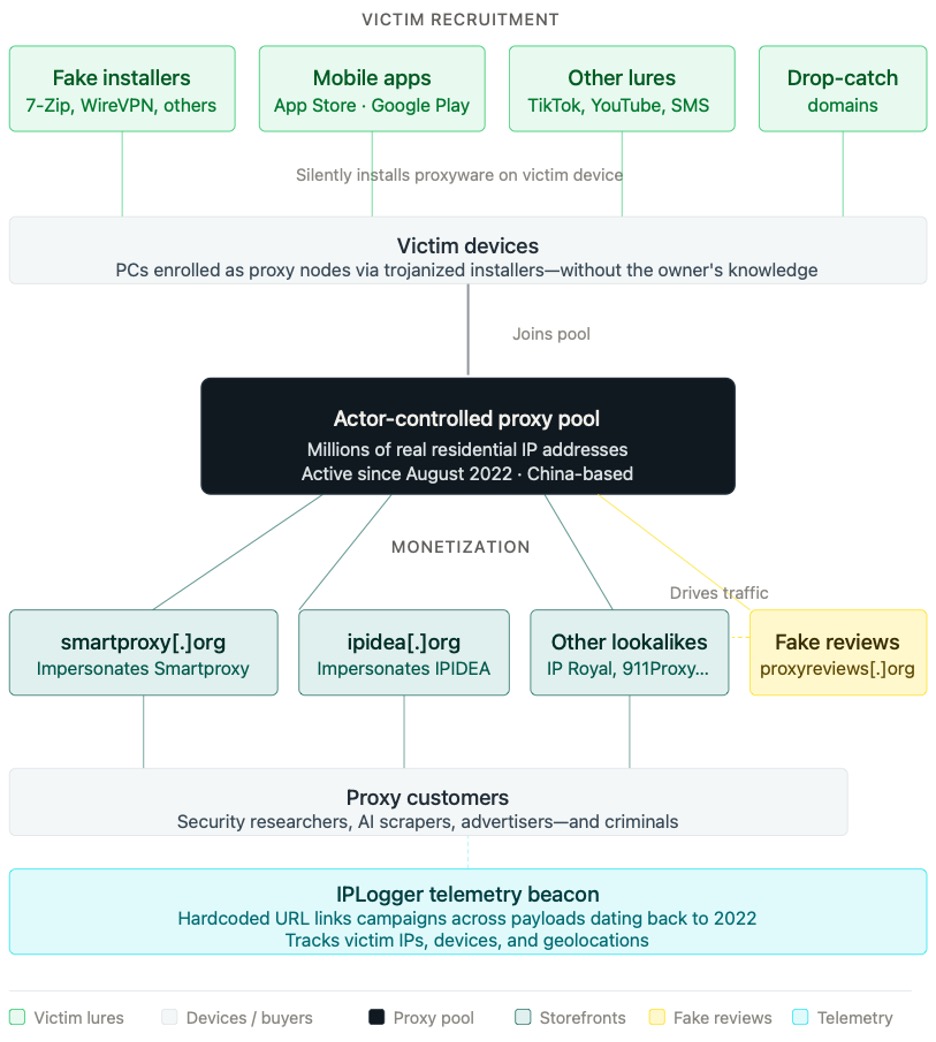
Отдельный трюк — покупка истёкших доменов с уже накопленной репутацией. В ход шли и похожие адреса: например, 7zip[.]com вместо настоящего 7-zip[.]org. Однако инфраструктура Lurking Lizard использовалась не только для фейкового 7-Zip.
Исследователи нашли поддельные установщики WhatsApp (принадлежит корпорации Meta, признанной экстремистской и запрещённой в России), псевдоинструменты для скачивания TikTok и YouTube, а также WireVPN. Кампания цепляла пользователей Windows, macOS и Android. Одно Android-приложение под брендом WireVPN набрало более 1 млн загрузок, хотя неясно, насколько они были органическими.
Схема работает в два этапа: сначала жертв заманивают троянизированными установщиками, приложениями и сайтами-двойниками, а затем заражённые устройства продают как часть прокси-сети. В итоге чужой телевизор, ноутбук или смартфон может внезапно стать транспортом для подозрительного трафика, а проблемы прилетят владельцу IP.



