













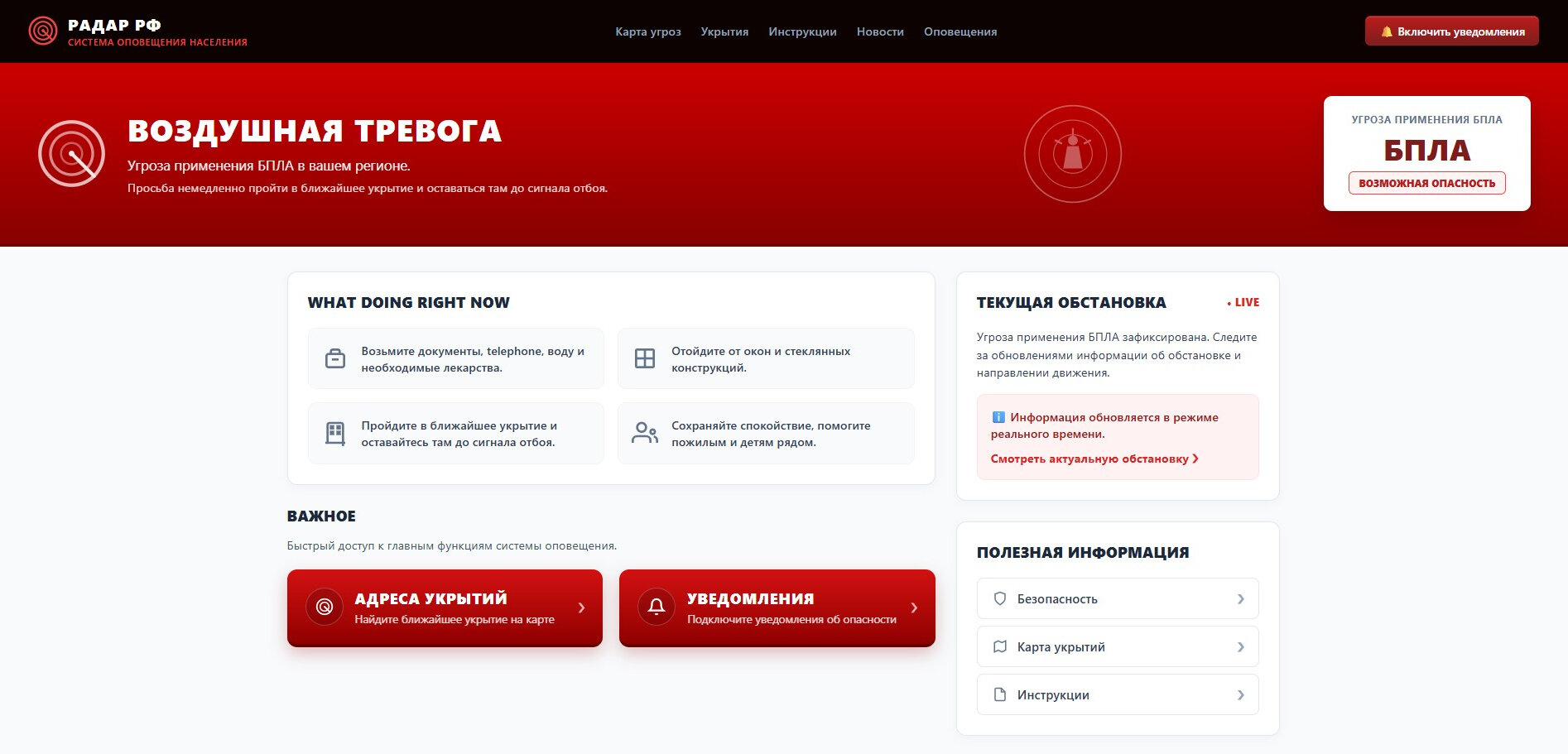
Киберпреступники придумали новую схему обмана, в которой жертва сама набирает номер мошенников. Специалисты компании «Эфшесть/F6» обнаружили сеть поддельных сайтов «Радар РФ» и «Ваша тревога», якобы предназначенных для оповещения об атаках беспилотников и поиска ближайших укрытий.
Сценарий рассчитан на панику. Главные страницы таких ресурсов буквально кричат красными предупреждениями: «Воздушная тревога», «Угроза», «Немедленно пройдите в укрытие». Пользователю предлагают подключить экстренные уведомления или посмотреть карту убежищ.
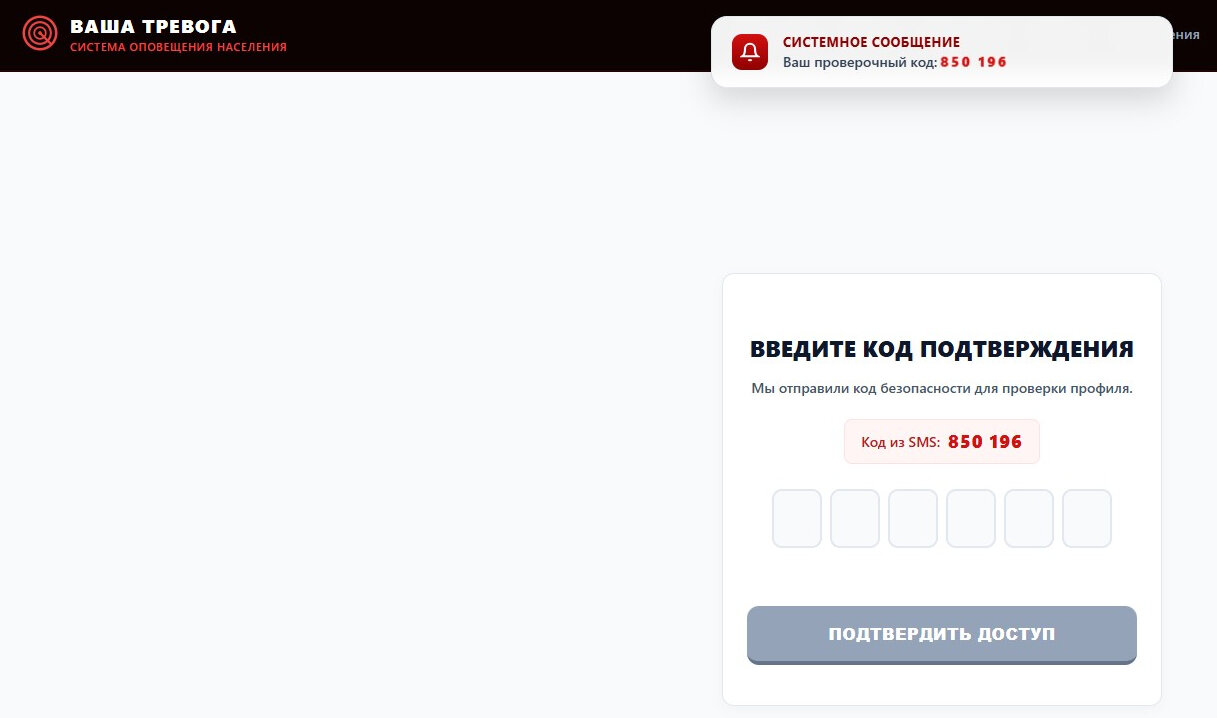
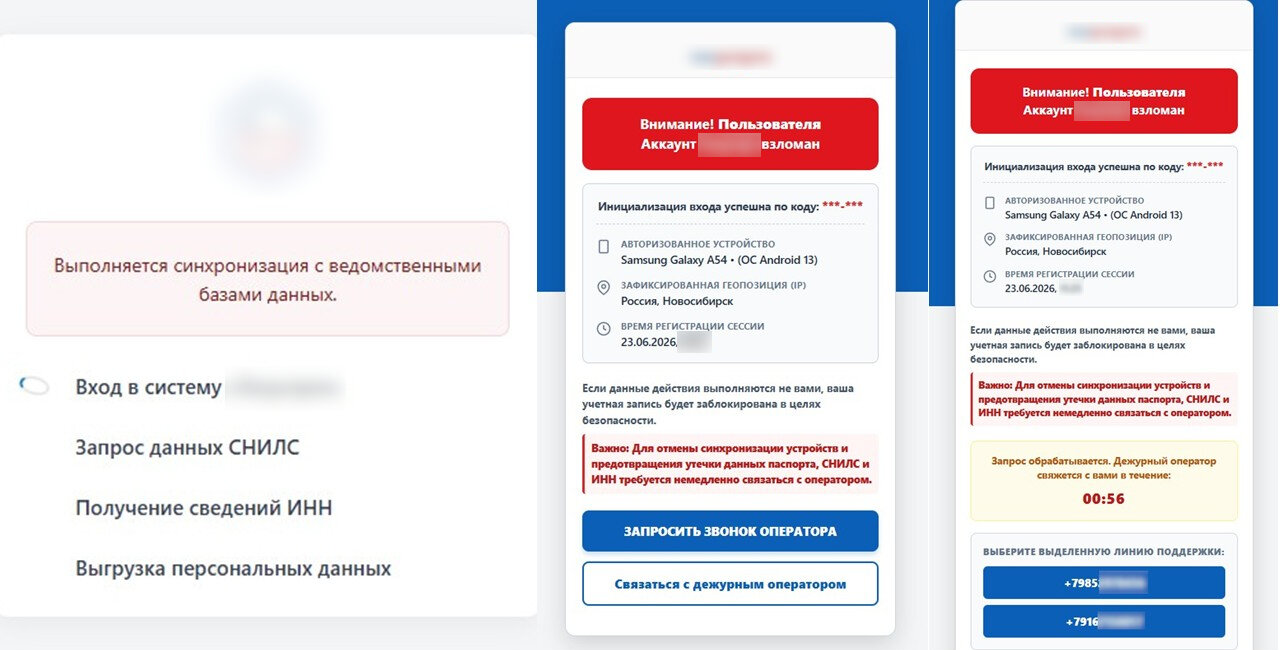
Дальше начинается спектакль. Сайт показывает якобы код подтверждения, причем никакого СМС не приходит, комбинация просто появляется на экране. После ввода цифр запускается анимация синхронизации с государственными сервисами: якобы запрашиваются данные СНИЛС, ИНН и другая информация.
Финальный акт — сообщение о том, что аккаунт на госпортале взломан. Для спасения предлагают самостоятельно позвонить на выделенную линию поддержки. На другом конце провода уже ждут операторы мошеннического кол-центра, которые могут разыгрывать любые сценарии — от финансирования террористов до требований срочно перевести деньги на безопасный счет или выполнить указания лжесотрудников спецслужб.
По данным F6, первые такие сайты появились 22 июня. Домены содержали слово radar, позже злоумышленники сменили оформление и начали использовать название «Ваша тревога». Предполагается, что ссылки распространяют через телеграм-каналы, районные и домовые чаты, а также комментарии под публикациями.
По инициативе CERT F6 за четыре дня уже заблокированы пять мошеннических ресурсов, однако злоумышленники продолжают регистрировать новые.
Если вас пытаются запугать взломом аккаунта и предлагают перезвонить по указанному номеру, перед вами мошенники. Проверять информацию нужно только через официальные сайты и приложения государственных сервисов.



