













Google, видимо, решила, что фитнес-браслетам и умные часам пора на пенсию. Компания представила технологию, которая позволяет измерять пульс и частоту сердечных сокращений в состоянии покоя с помощью обычной фронтальной камеры смартфона.
Никаких датчиков на запястье, никаких ремешков и дополнительных устройств. Всё, что нужно, — собственное лицо.
Система получила название Passive Heart Rate Monitoring (PHRM). Работает она любопытно: после разблокировки смартфона по лицу фронтальная камера записывает короткое восьмисекундное видео, а встроенная ИИ-модель анализирует едва заметные изменения цвета кожи, возникающие из-за кровотока.
Человеческий глаз таких изменений не видит, а вот алгоритмы машинного обучения — вполне.
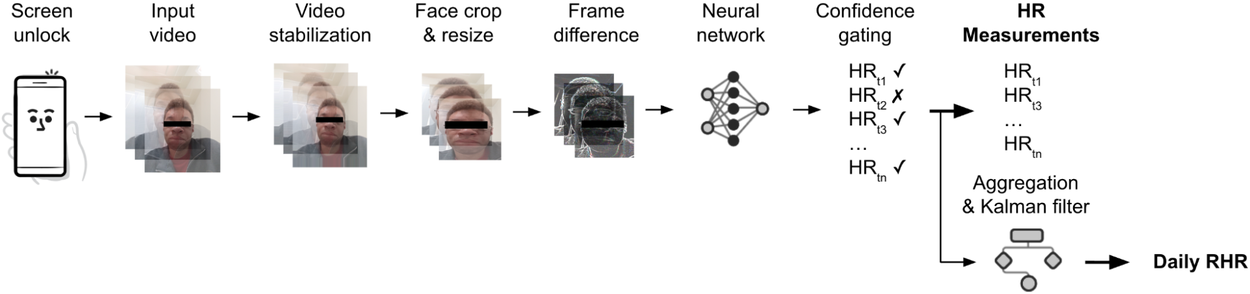
По данным Google, точность системы оказалась неожиданно высокой. При оценке пульса в состоянии покоя результаты отличались от показателей фитнес-браслета Fitbit Charge 6 менее чем на пять ударов в минуту.
Для обучения и тестирования модели компания использовала более 350 тысяч видеозаписей почти 700 участников с разными оттенками кожи. Более того, исследователи проверяли технологию не только в лаборатории, но и в реальной жизни. Добровольцы больше недели ходили со своими смартфонами, одновременно используя Fitbit и медицинское оборудование для контроля сердечного ритма.
Результаты оказались убедительными, чтобы Google всерьёз заговорила о будущем такого подхода. Впрочем, до идеала ещё далеко. Исследователи признают, что системе пока сложнее стабильно получать данные у людей с тёмными оттенками кожи. Также на точность могут влиять разговоры, движения головы и другие обычные действия.
Есть и вопрос приватности. Всё-таки технология предполагает регулярный анализ изображения лица пользователя. В Google уверяют, что обработка может выполняться непосредственно на устройстве без передачи данных в облако.



