
















Компания Security Vision выпустила очередное обновление платформы Security Vision 5. В новом релизе разработчики сделали акцент на доработке механизмов корреляции событий, автоматизации процессов и упрощении администрирования системы.
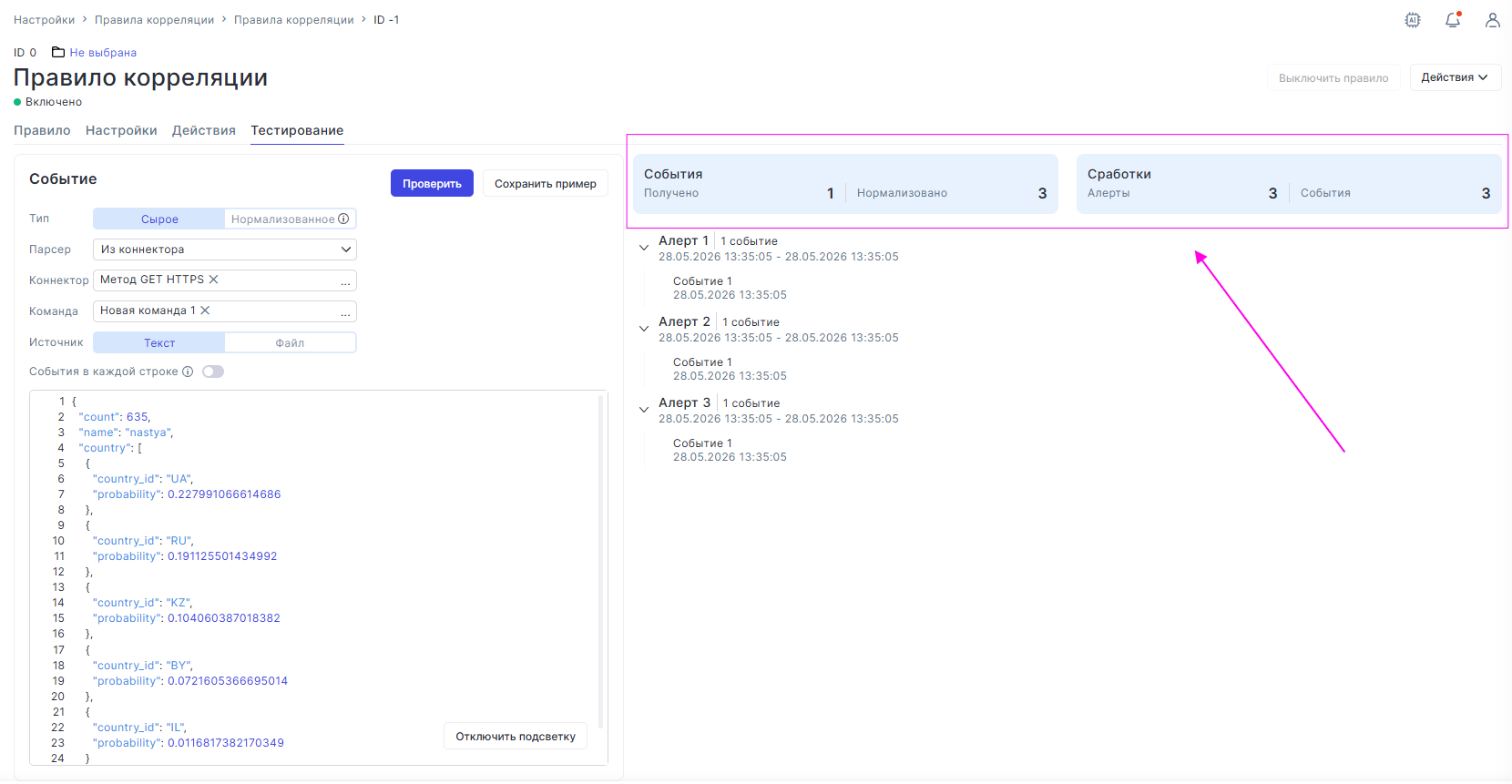
Одним из самых заметных изменений стало появление встроенного тестирования правил корреляции. Теперь специалисты могут проверить работу правила ещё на этапе настройки, не дожидаясь появления реальных событий в инфраструктуре. Для этого в редакторе появилась отдельная вкладка «Тестирование».
Кроме того, платформа научилась работать с правилами в формате Sigma. Для них добавлена автоматическая проверка кода, а сами правила можно экспортировать и импортировать через YAML-файлы. Это упрощает перенос настроек между Security Vision и другими системами, поддерживающими Sigma.
Разработчики также расширили возможности автоматизации. Теперь при запуске рабочих процессов из графа объектов можно переопределять входные параметры в зависимости от конкретного сценария. Проще говоря, один и тот же процесс можно использовать в разных условиях без создания множества его копий.
Ещё одно изменение касается обработки данных. В механизмах парсинга появились динамические источники данных, включая переменные и входные параметры. Это позволяет строить более гибкие сценарии обработки информации и использовать данные, полученные непосредственно во время выполнения автоматизированных процессов.
Обновления затронули и пользовательский интерфейс. В новой версии переработаны редакторы объектов, справочников и карточек. Настройка структуры данных стала более удобной, а управление отображением карточек — более наглядным.
Изменения получили и инструменты развертывания платформы. В мастер установки добавили возможность заранее указывать внешний URL для сервисов, что упрощает настройку в сложных инфраструктурах. Также появились дополнительные параметры командной строки, включая просмотр версии платформы и справочную информацию по установке.
В итоге обновление получилось скорее инфраструктурным, чем визуальным. Новые функции ориентированы на специалистов, которые занимаются настройкой корреляции, автоматизацией процессов и сопровождением платформы в крупных ИТ- и ИБ-проектах.



