















Исследователи из Cyble Research and Intelligence Labs (CRIL) обнаружили новую масштабную кампанию по распространению Android-трояна, нацеленного на кражу банковских данных и учётных записей криптовалютных сервисов. Вредоносная программа уже атакует пользователей как минимум в десяти странах и маскируется под популярные приложения, включая TikTok.
Атака начинается с поддельных ссылок на загрузку приложений. После установки дроппер показывает пользователю убедительное уведомление об обновлении Google Play и пошаговую инструкцию по выдаче необходимых разрешений.
Под видом компонента «Google Play Services» вредоносная программа получает доступ к службе специальных возможностей Android (Accessibility Service), что позволяет ей закрепиться в системе и получить расширенный контроль над устройством.
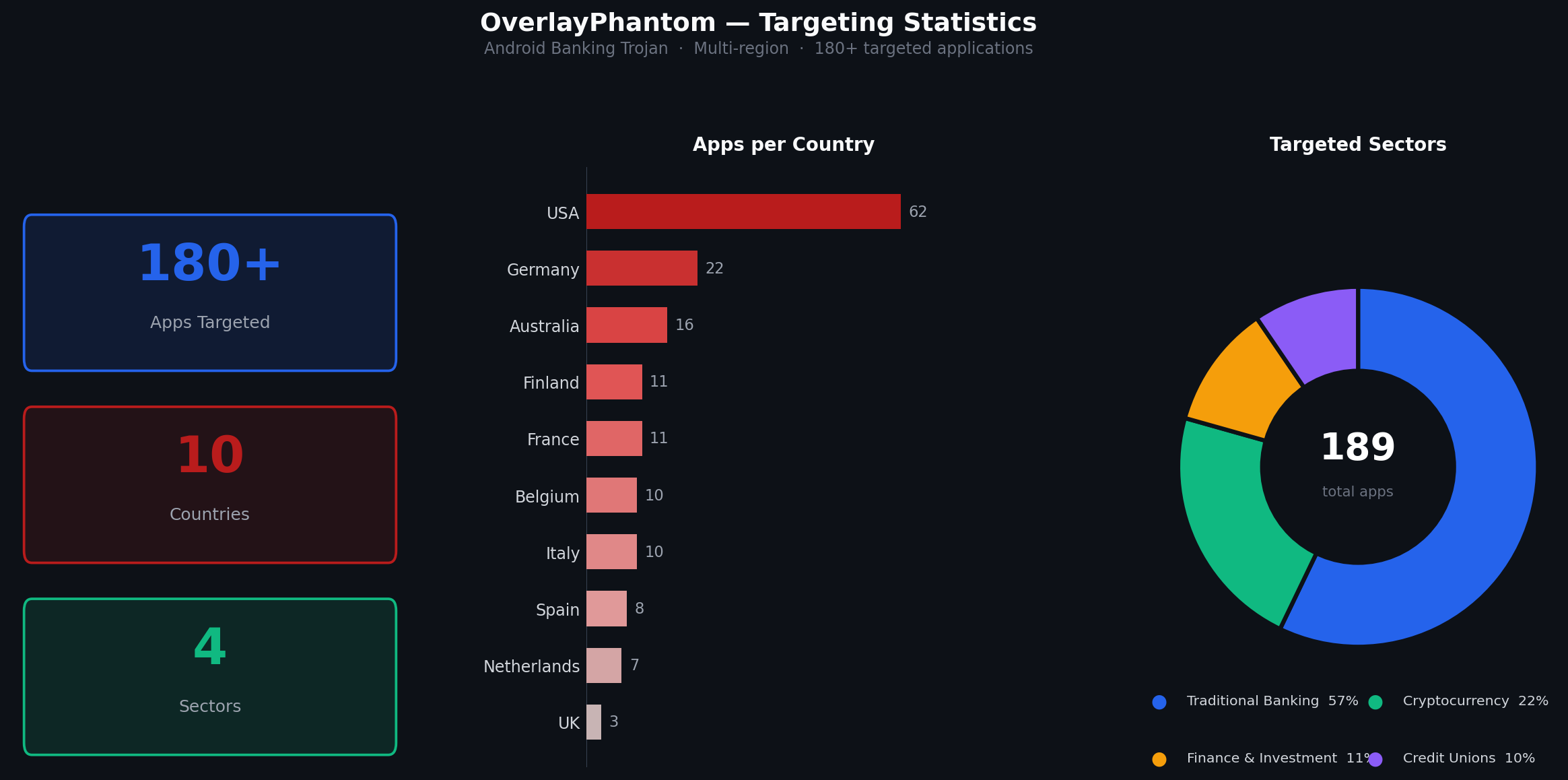
Троян постоянно отслеживает, какие приложения запускает пользователь, и сверяет их со встроенным списком целей. В этот список входят более 180 банковских, финансовых и криптовалютных приложений. Когда жертва открывает одно из них, поверх легального интерфейса появляется фишинговая форма, визуально практически неотличимая от настоящей страницы входа.
Пользователь вводит логин, пароль или код подтверждения, даже не подозревая, что данные отправляются злоумышленникам.
Возможности трояна этим не ограничиваются. Исследователи обнаружили поддержку более 30 удалённых команд. Операторы могут управлять буфером обмена, имитировать нажатия на экран, показывать поддельные уведомления и выполнять другие действия на заражённом устройстве.
Отдельную угрозу представляет функция потоковой передачи изображения с экрана. Используя штатный API Android MediaProjection, вредоносная программа непрерывно захватывает экран устройства и отправляет снимки на сервер злоумышленников в формате JPEG. Это позволяет практически в реальном времени наблюдать за финансовыми операциями жертвы и перехватывать одноразовые коды подтверждения.
Инфраструктура управления трояном разделена на несколько каналов связи. Один порт используется для команд операторов, второй — для телеметрии заражённого устройства, третий — для передачи видеопотока с экрана.



