














ИИ воскресил легендарную игру «Поле Чудес 2» из 1993 года, исходников не было вообще. Разработчик Денис Ширяев рассказал, что с помощью ИИ Claude Fable 5 смог восстановить и перенести в браузер культовую DOS-игру «Поле Чудес 2», вышедшую ещё в 1993 году.
Главная интрига в том, что оригинальные исходники проекта были утеряны много лет назад. Фактически от игры остался только исполняемый файл.
Вместо ручной декомпиляции и многомесячной реконструкции Ширяев решил проверить возможности ИИ и скормил Claude Fable 5 бинарник старой игры.
По словам разработчика, нейросеть проанализировала машинный код, восстановила игровую логику, извлекла графические ресурсы и переписала проект на TypeScript. Весь процесс занял около двух часов, а расходы на API составили примерно 100 долларов.
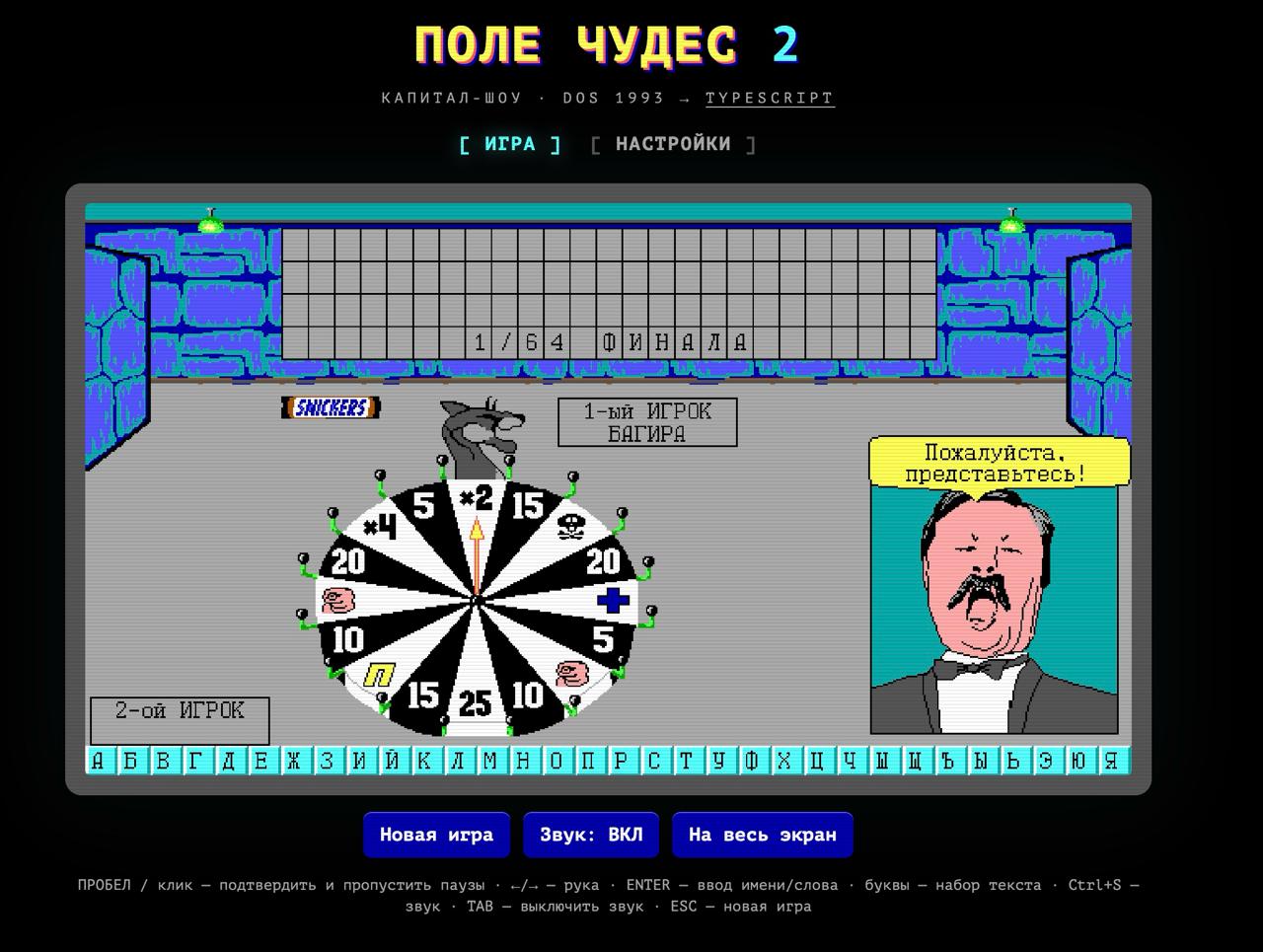
В итоге появилась полноценная браузерная версия «Поля Чудес 2». В ней сохранены заставка, ввод имени игрока, турнир из восьми этапов, знаменитое колесо с секторами, мини-игра со шкатулками и даже внутриигровой магазин призов.
Более того, автор отдельно восстановил оригинальный генератор случайных чисел, благодаря чему некоторые игровые сценарии могут совпадать с DOS-версией почти один в один.
Сам Ширяев называет Fable и Mythos лазером для разработки ПО. По его словам, современные ИИ-системы уже способны выполнять задачи, которые ещё недавно потребовали бы серьёзной команды реверс-инженеров и десятков часов ручной работы.
Проект опубликован на GitHub под лицензией MIT. Исходный код доступен всем желающим, а поиграть в восстановленную версию можно прямо в браузере.



