В экосистеме JavaScript обнаружили очередную, но особенно неприятную атаку на цепочку поставок. В каталоге NPM более полугода распространялся вредоносный пакет lotusbail, который выдавал себя за библиотеку для работы с WhatsApp API (принадлежит признанной в России экстремистской организации и запрещённой корпорации Meta) — и при этом тихо воровал переписку, контакты и учётные данные пользователей.
На находку обратили внимание исследователи из Koi Security, опубликовав подробный технический разбор. К моменту обнаружения пакет успели скачать более 56 тысяч раз, что делает ситуацию далеко не нишевой.
В отличие от многих зловредов в NPM, которые ломаются или выдают себя странным поведением, lotusbail был практически идеальной подделкой. Его авторы просто склонировали популярную библиотеку @whiskeysockets/baileys, которая используется для работы с WhatsApp Web через WebSocket, и аккуратно встроили в неё вредоносный код.
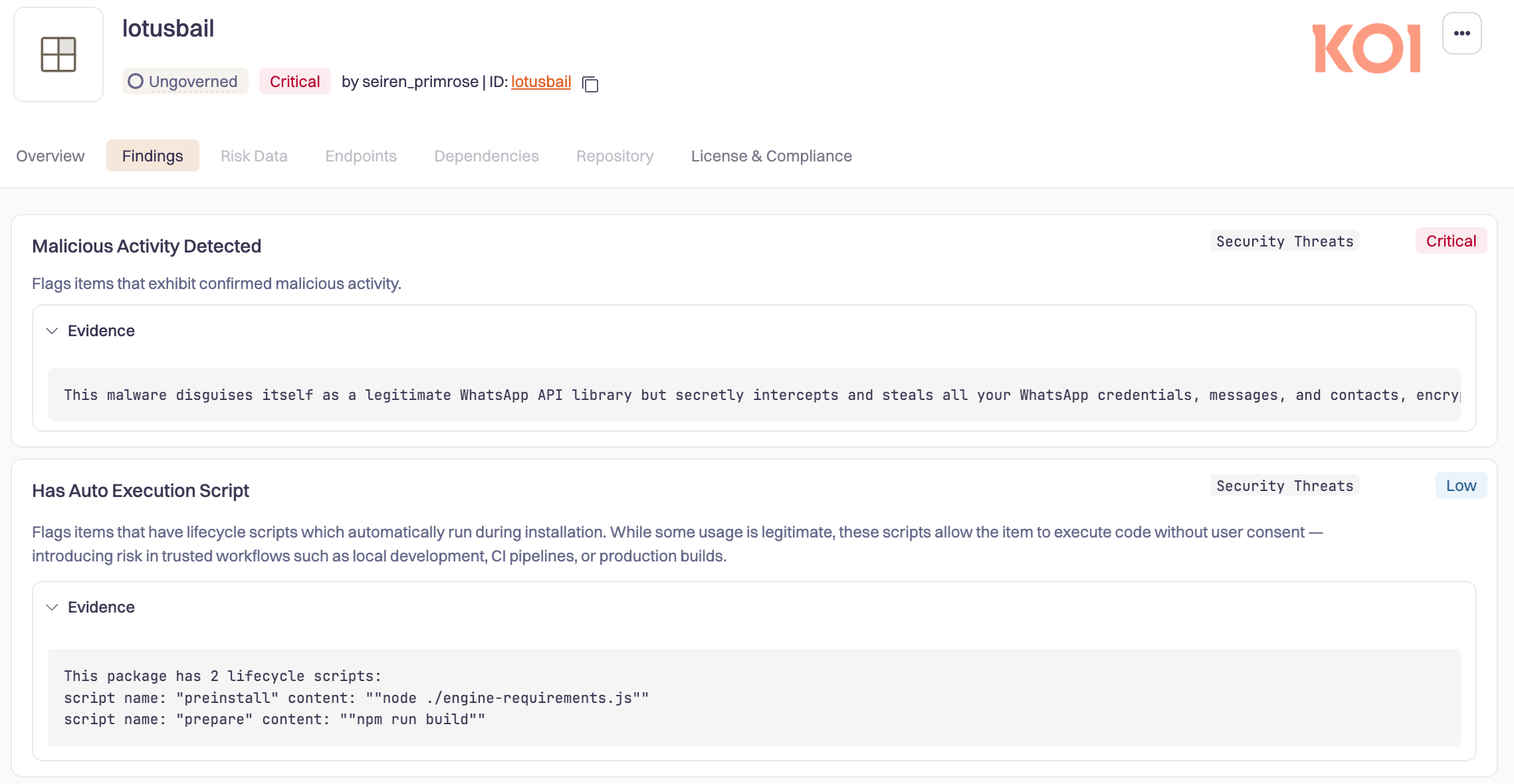
Снаружи всё выглядело легитимно: приложения на базе lotusbail спокойно отправляли и получали сообщения. Но параллельно библиотека:
- перехватывала все входящие и исходящие сообщения;
- собирала медиафайлы;
- вытаскивала списки контактов с номерами телефонов;
- сохраняла WhatsApp-сессии, токены и коды привязки устройств.
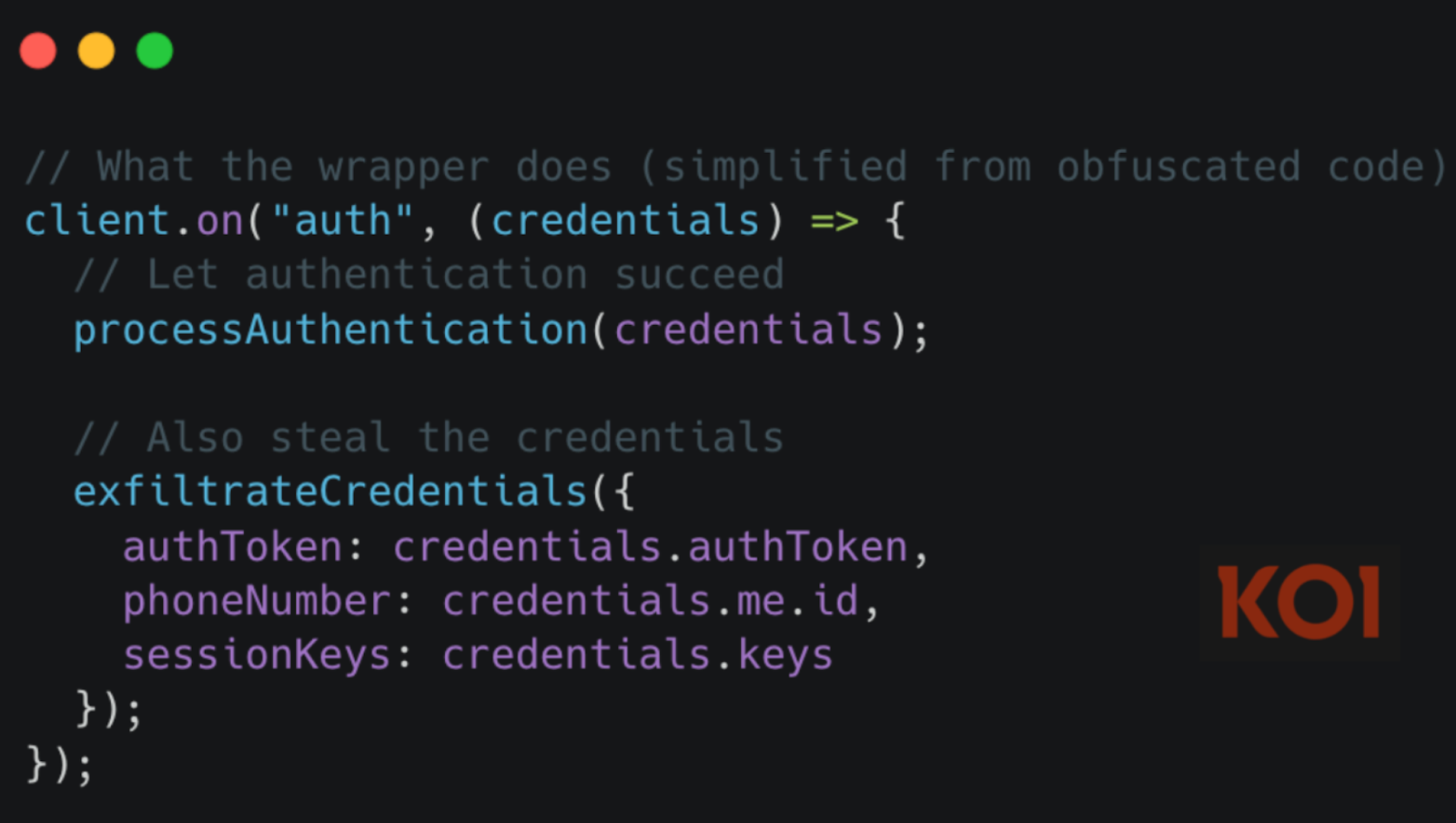
Причём перехватывались не только новые сообщения, но и исторические данные, доступные через API.
Самая опасная часть — использование механизма «сопряжение устройств» в WhatsApp. В коде пакета был зашит жёстко заданный, зашифрованный AES код привязки, который незаметно подключал устройство злоумышленника к аккаунту жертвы.
В результате атакующий получал постоянный доступ к WhatsApp-аккаунту, который сохранялся даже после удаления вредоносного пакета из проекта.
Проще говоря, удалить lotusbail недостаточно. Чтобы полностью закрыть дыру, жертве нужно вручную отвязать все устройства в настройках WhatsApp.
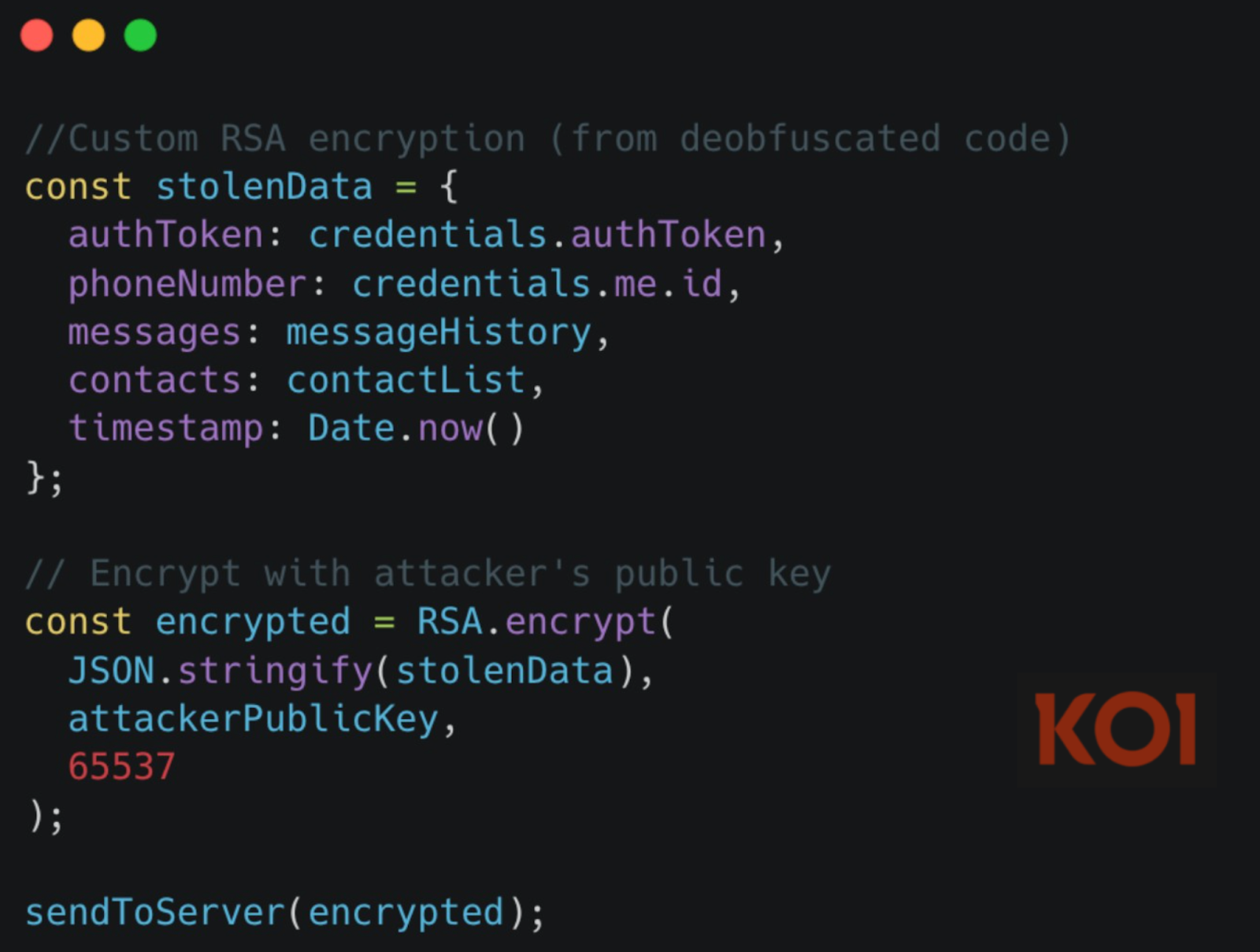
Собранные данные дополнительно шифровались с помощью кастомной реализации RSA. Это не имело отношения к сквозному шифрованию WhatsApp — цель была другой: спрятать утечки от систем мониторинга и сетевых средств защиты.
Эксперты отмечают, что атака отлично иллюстрирует главную проблему экосистемы open source: функциональность маскирует вредоносную логику. NPM остаётся одной из самых привлекательных целей для атак на цепочки поставок — из-за масштаба, доверия разработчиков и низкого порога публикации пакетов.
Ранее в новом докладе властей Великобритании прозвучала мысль, что разработка зашифрованных мессенджеров вроде WhatsApp теоретически может считаться «враждебной деятельностью».

















