














Киберпреступники развернули новую международную кампанию через WhatsApp (принадлежит корпорации Meta, признанной экстремистской и запрещённой в России), используя взломанные аккаунты пользователей для распространения вредоносных файлов. Под удар попали пользователи в Бразилии, Индии, Мексике, Великобритании, Испании, России и ряде других стран.
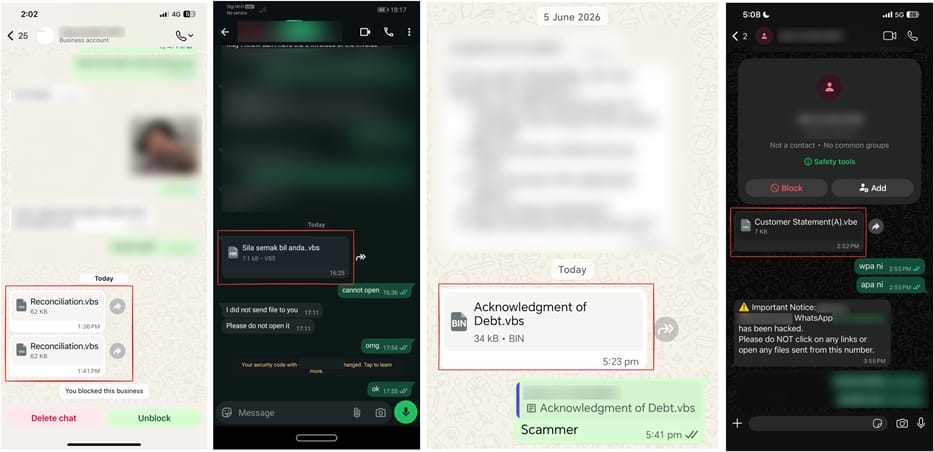
Об атаке сообщили специалисты «Лаборатории Касперского». Жертва получает сообщение от знакомого контакта в WhatsApp.
Внутри лежит файл с названием вроде финансового отчёта, счёта, платёжного документа или уведомления по аккаунту. Названия адаптированы под разные языки и регионы, что говорит о глобальном масштабе кампании.
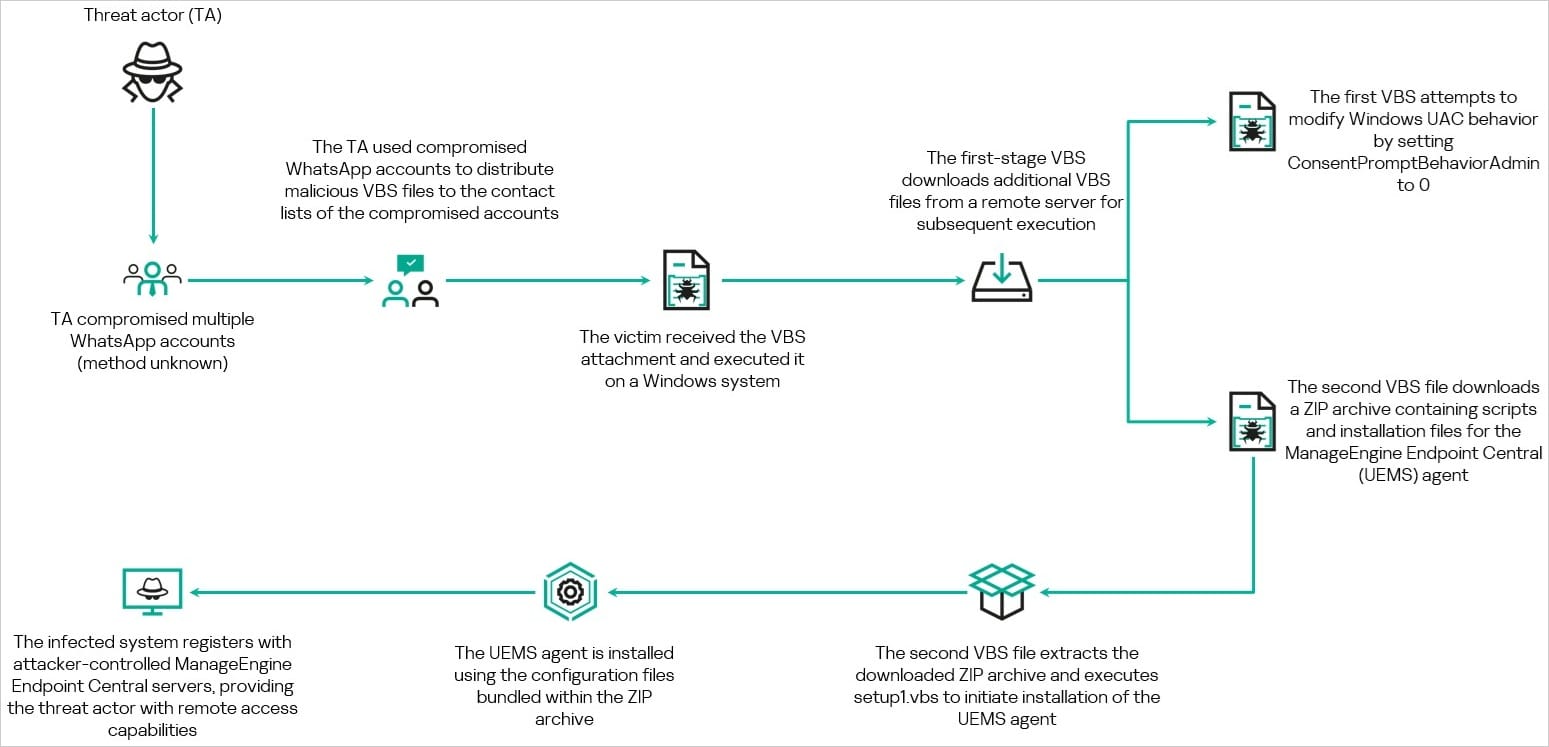
Но вместо документа пользователя ждёт вредоносный VBS-файл. Как выяснили исследователи, злоумышленники получают доступ к учётным записям WhatsApp и рассылают заражённые вложения по списку контактов. Каким именно способом компрометируются аккаунты, пока неизвестно.
После запуска файла на компьютере под управлением Windows начинается цепочка заражения. Скрипт скачивает дополнительные компоненты, отключает часть защитных механизмов системы и загружает архив с программой ManageEngine Endpoint Central.
Сама по себе ManageEngine Endpoint Central является легитимным корпоративным инструментом удалённого администрирования, который используют ИТ-специалисты для управления рабочими станциями. Однако в данном случае программа устанавливается скрытно и подключается к серверам злоумышленников.
В результате атакующие получают удалённый доступ к компьютеру жертвы практически на правах администратора.
Отдельную опасность представляет версия WhatsApp Desktop. Если в WhatsApp Web вредоносный файл сначала необходимо скачать, то в настольном клиенте Windows такой VBS-файл может запускаться напрямую через Windows Script Host.
Исследователи пока не связывают атаку с конкретной группировкой. Однако в инфраструктуре кампании были обнаружены следы использования китайского языка и пересечения с активностью известных зловредов ValleyRAT и Gh0st RAT.
Эксперты советуют не доверять вложениям даже от знакомых контактов. Если кто-то неожиданно прислал файл с финансовым отчётом или счётом, лучше уточнить его происхождение через звонок или другое средство связи. А любые загруженные файлы перед открытием стоит проверять антивирусом.



