














Исследователи обнаружили новый шпионский инструмент для Android, который маскировался под приложение для обновления телефона. Зловред получил название Morpheus и, по данным Osservatorio Nessuno, может быть связан с итальянской компанией IPS, давно работающей на рынке технологий для перехвата коммуникаций по запросу госструктур.
Morpheus нельзя назвать технически изящным шпионским софтом уровня NSO Group или Paragon Solutions. Здесь нет заражения через 0-click уязвимости. Схема проще и грубее: жертву нужно убедить установить приложение самостоятельно.
По данным исследователей, в атаке участвовал мобильный оператор. Сначала у цели намеренно пропадал мобильный интернет, а затем приходило СМС с предложением установить приложение якобы для обновления телефона и восстановления доступа к сети. На деле это и был шпионский инструмент.

После установки Morpheus использовал функции специальных возможностей Android. Это позволяло ему читать данные с экрана и взаимодействовать с другими приложениями. Затем зловред показывал фейковое обновление, имитировал экран перезагрузки и подсовывал поддельный запрос от WhatsApp (принадлежит корпорации Meta, признанной экстремисткой и запрещённой в России) с просьбой подтвердить личность биометрией.
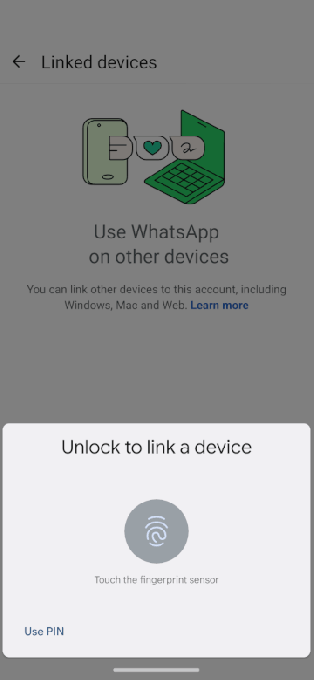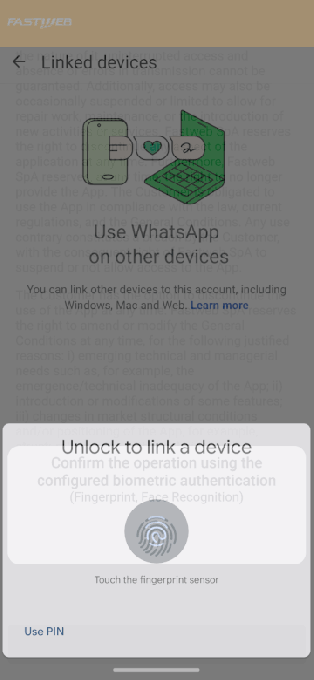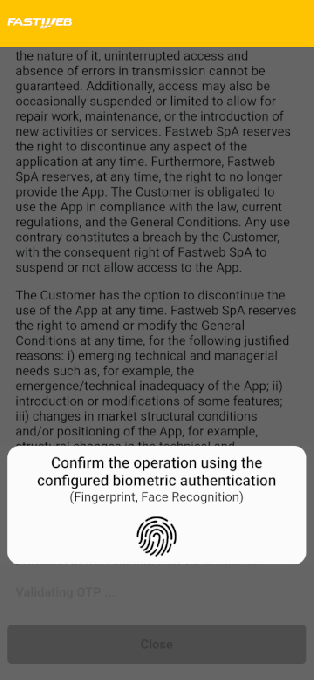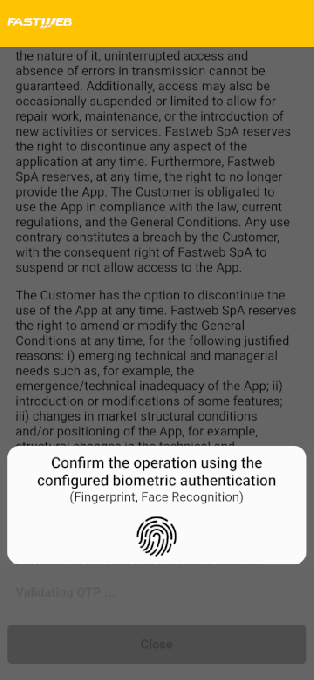
В реальности это действие давало шпионскому софту доступ к аккаунту WhatsApp: устройство добавлялось к учётной записи жертвы. Такой приём уже встречался в кампаниях правительственных хакеров.
Исследователи не раскрывают личность цели, но считают, что атака могла быть связана с политическим активизмом в Италии. По их словам, такие точечные атаки в этой среде становятся всё более привычными.



