В прошлом году в Сеть попало 667 млн записей с персональными данными. Это почти в 3 раза больше, чем в 2021 году и в 4,5 раза превышает население России. 80% утечек носят “гибридный” характер.
Свежие цифры по утечкам приводятся в исследовании ГК InfoWatch “Россия: утечки информации ограниченного доступа в 2022”. За год случился почти троекратный скачок — 667,6 млн записей “утекли” в открытый доступ.
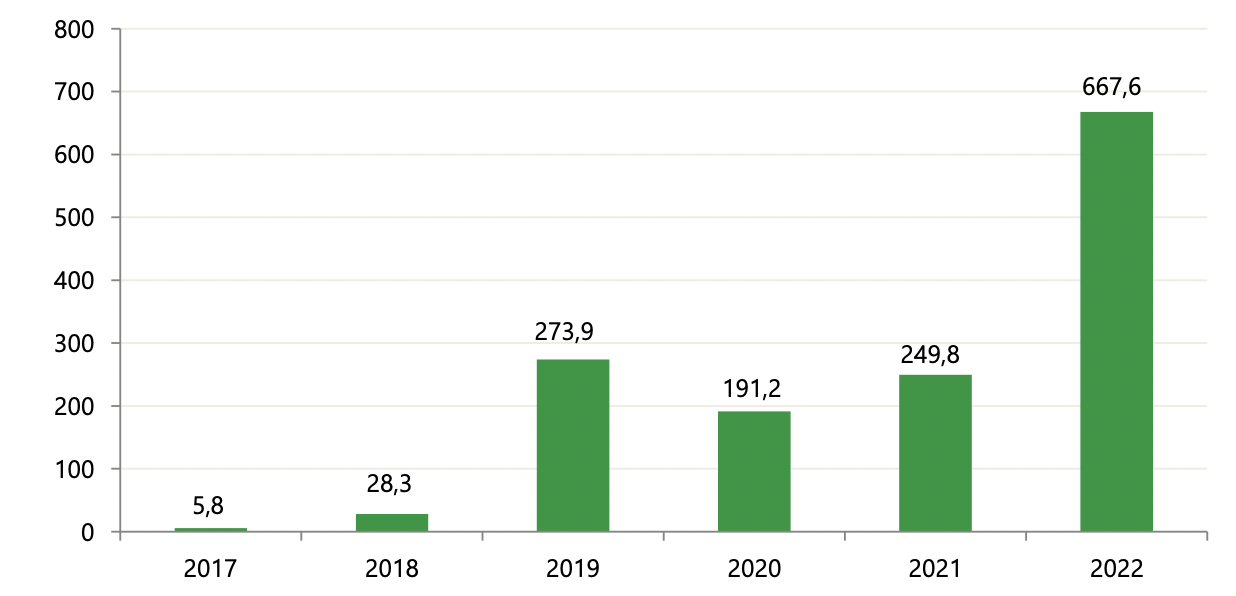
При этом средняя утечка “потяжелела” на четверть и составила более 940 тыс. записей.
Крупными базами уже оперируют даже небольшие региональные компании, утечка подобной информации может затронуть многие тысячи людей, отмечается в исследовании.
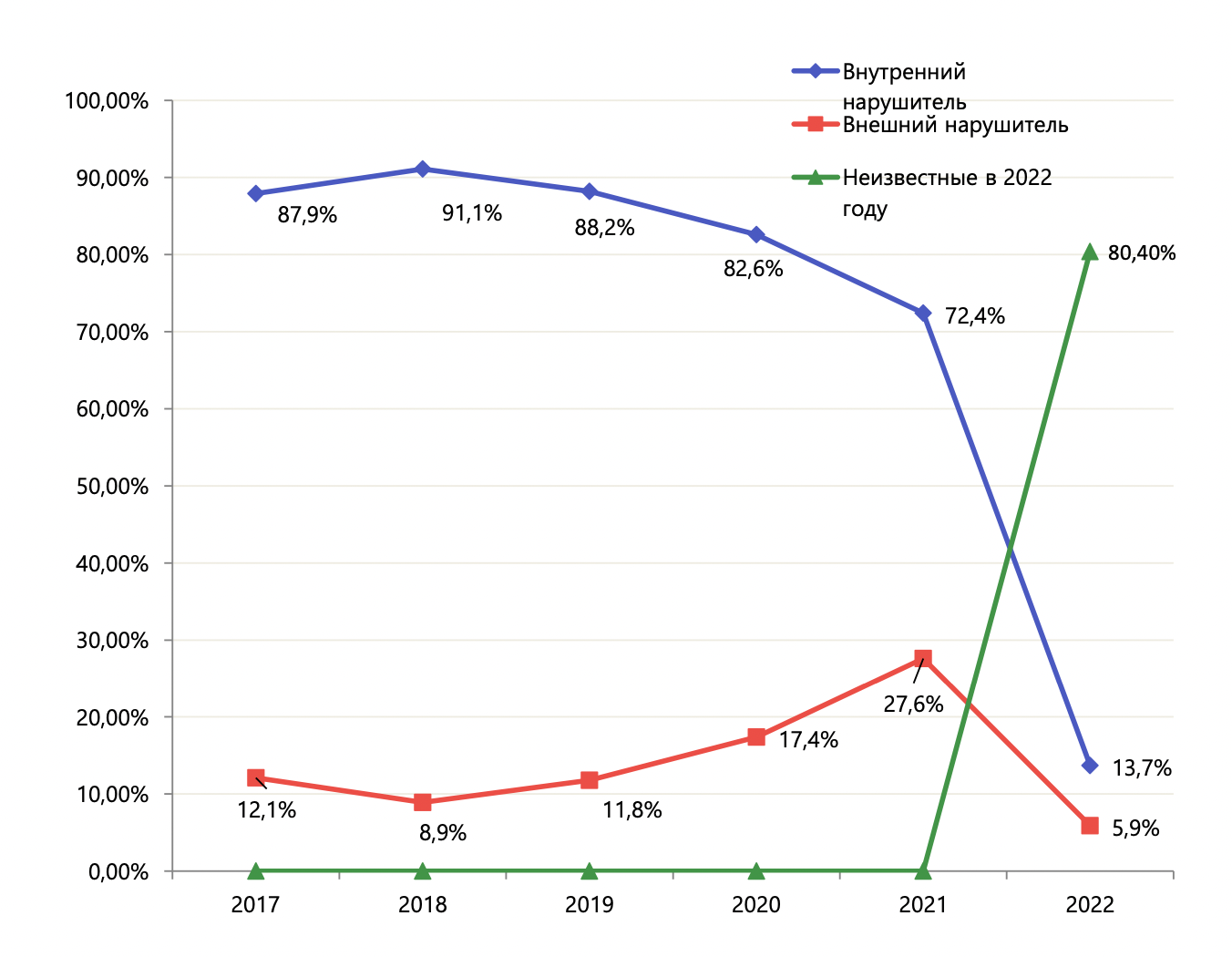
Более 80% утечек имеют гибридный вектор воздействия, когда в краже информации могли участвовать как внешние, так и внутренние нарушители.
Во многом это связано с большими объемами данных, которые публикуются на “теневых площадках”. Проследить источник часто невозможно, признают эксперты.
Скорее всего, значительная часть этих “сливов” так или иначе связана с действиями хакеров, но во многих случаях вероятно участие персонала компаний.
В России, как и во всем мире, еще с пандемии растет доля утечек информации умышленного характера. Каждая единица таких конфиденциальных сведений имеет денежный эквивалент на черном рынке.
При этом существенно упало количество случайных утечек. Это говорит об успехах организаций в практике использования DLP-систем, спрос на которые резко вырос в пандемийные годы, отмечается в исследовании.
“2022 год ознаменовался наивысшим объёмом утечек чувствительной информации – в совокупности порядка 1,4 млрд строк, из которых 660 млн, как подсчитали коллеги из Infowatch, – данные, относящиеся к гражданам”, – комментирует цифры менеджер по продукту Ankey IDM компании “Газинформсервис” Иван Корешков. По-прежнему высока доля утечек с участием инсайдеров – около 76-80%.
Такая природа утечек который год подряд доказывает, что разграничение доступа и понятные политики его предоставления является одной из ключевых превентивных мер, настаивает Корешков. По его словам, проще ограничить доступ до необходимого уровня, чем потом выяснять, каким способом информация утекла.
“Неоднократно слышал, как пересылки тех или иных документов с грифом КТ замечала DLP-система уже по факту отправки”, – рассуждает Корешков. – Но ведь гораздо проще дать временный доступ на ознакомление с такой информацией или вообще не предоставлять его сотруднику без служебной необходимости”.
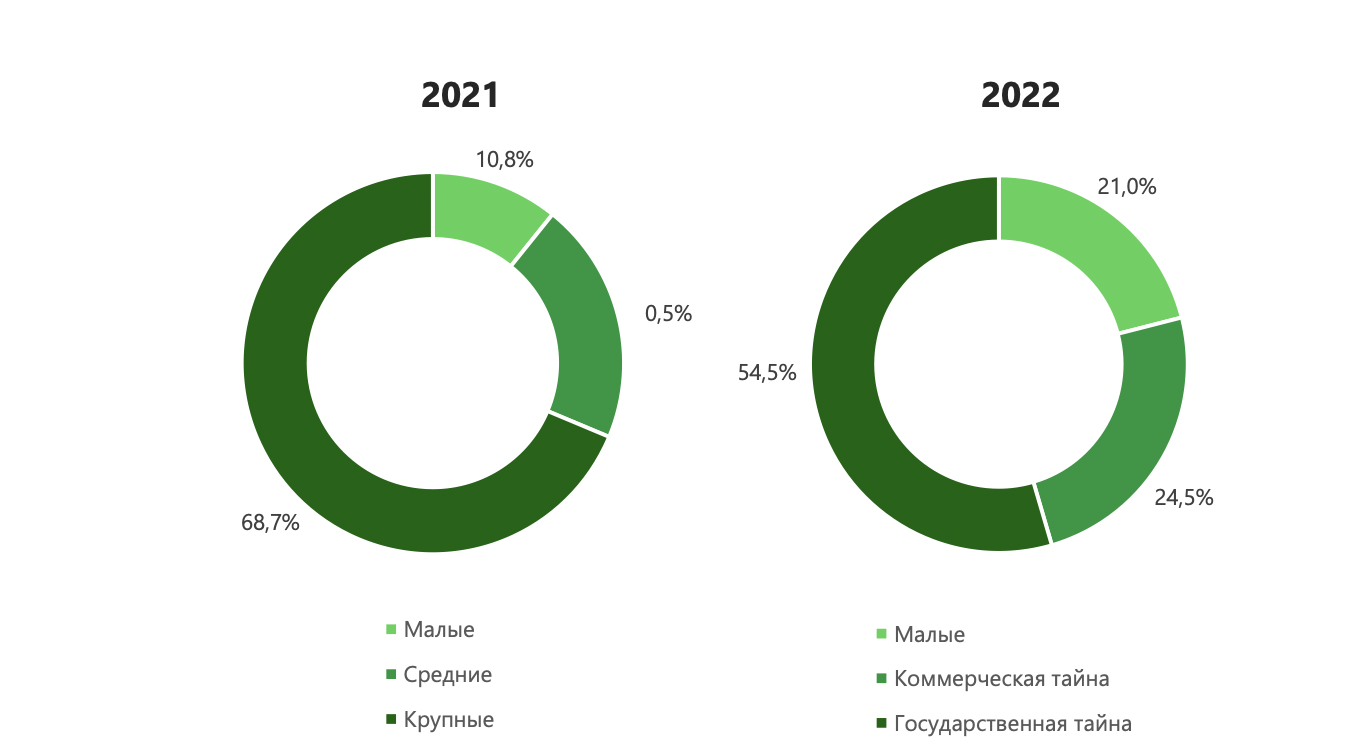
В 2022 году вдвое выросла доля компрометации сведений, составляющих коммерческую тайну. Хакеры активно взламывают торговые и производственные организации, отмечают специалисты InfoWatch.
Сильно страдает и ретейл. В этой группе утечек стало почти в пять раз больше. Такой всплеск свидетельствует о низком уровне защиты информационных активов в розничных сетях, общепите и службах доставки, подчеркивают эксперты. При этом в базах таких компаний содержится значительное количество ПДн и платежной информации.
Под прицелом кибервзломщиков и малый бизнес. Даже небольшие компании все чаще имеют дело с конфиденциальной информацией большого объема. Их хранилища могут содержать миллионы записей.
Поймать нарушения, связанные с утечками информации, всё сложнее, приходят к выводу эксперты. Среди причин: запутанность современной ИТ-инфраструктуры, “удаленка”, скрытный характер атак и нарушений, адаптация приемов фишинга и социальной инженерии.
Еще сложнее найти в этой лавине утечек виновника, отмечается в исследовании.
Ответ на вопрос, кто стоит за той или иной утечкой — внешние нарушители (хакеры), сотрудники (по своей инициативе или в сговоре с хакерами), подрядчики, — все чаще не имеет однозначного ответа.


















