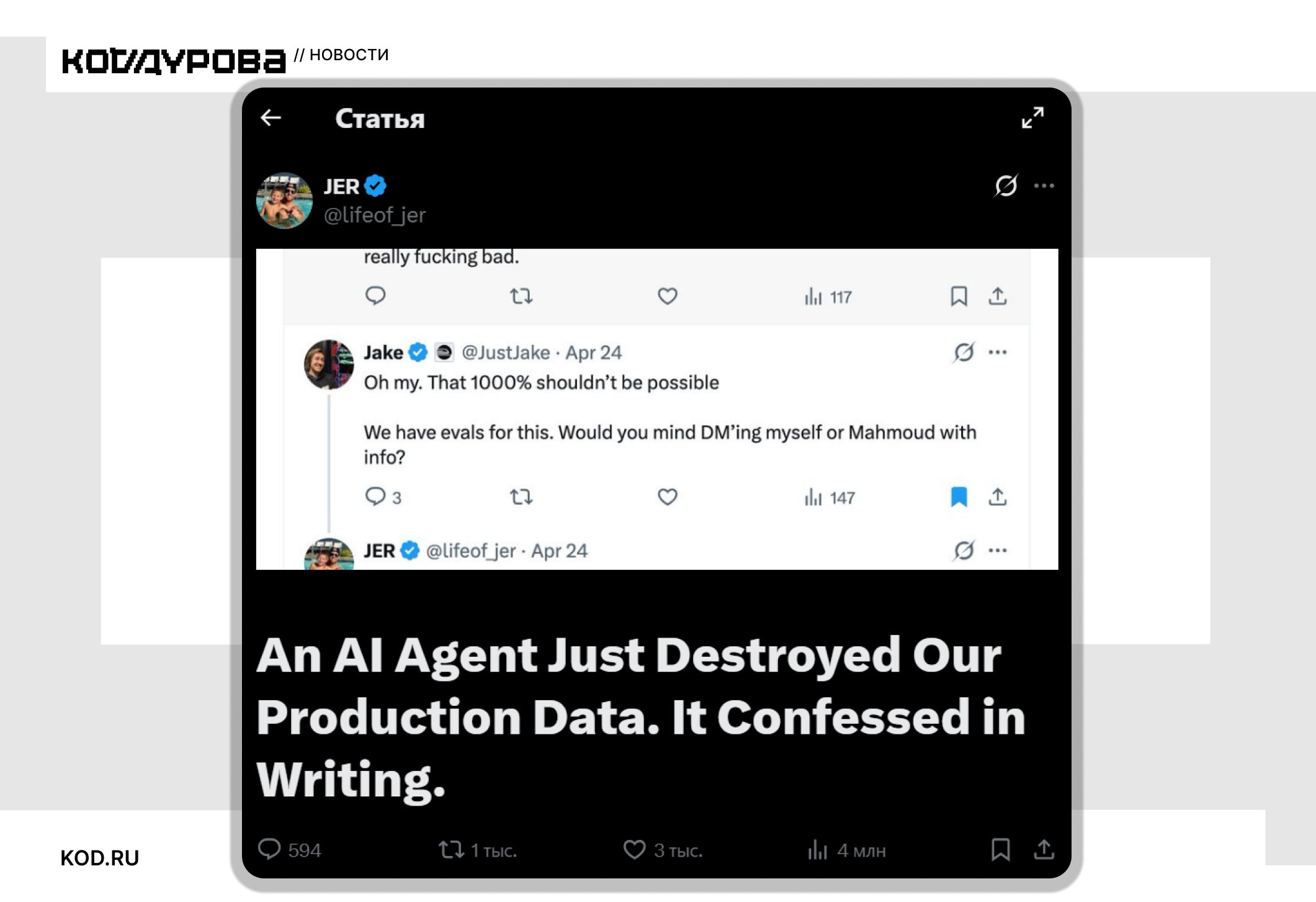







Компания PocketOS потеряла данные клиентов из-за действий ИИ-агента. Он обнаружил расхождения в учётных данных и решил самостоятельно устранить проблему, однако в результате удалил основную клиентскую базу и все резервные копии.
Об инциденте сообщил глава PocketOS Джер Крейн на своей странице в соцсети X:
«Вчера днём редактор Cursor на базе Claude Opus 4.6 удалил нашу базу данных и все резервные копии на уровне томов одним API-запросом к Railway, нашему поставщику инфраструктуры. На это ушло 9 секунд».
Как выяснилось, ассистент нашёл API-токен в одном из файлов, который не был связан с текущей задачей. Токен предназначался для работы с пользовательскими данными, но при этом давал полный доступ к облачной инфраструктуре, включая возможность удаления данных.
После инцидента Джер Крейн раскритиковал не только разработчиков ИИ-ассистента, но и Railway: по его словам, API-токен обладал явно избыточными правами. В итоге ошибка пользователя могла привести к крайне серьёзным последствиям. Ещё одной серьёзной недоработкой стало хранение резервных копий рядом с продуктивной базой.
PocketOS — стартап, развивающий сервис аренды автомобилей. У компании около 1600 клиентов.