







Команда исследователей из Швейцарии выявила новую уязвимость, позволяющую обойти защиту PIN-кодом при бесконтактной оплате банковскими картами Visa. Злоумышленники могут использовать эту брешь для совершения несанкционированных покупок на большие суммы.
По словам специалистов, обойти PIN-коды можно незаметно, не вызывая никаких подозрений у платёжной системы. Со стороны это будет выглядеть как стандартная операция, которую владелец карты провёл с помощью установленного на смартфоне приложения.
На деле же атакующий расплачивается данными украденной бесконтактной карты Visa.
Как отметили исследователи в отчёте (PDF), успешная атака требует четырёх компонентов: два Android-смартфона, специальное Android-приложение (специалисты сами его разработали) и бесконтактная карта Visa. Упомянутое приложение должно быть установлено на каждом из двух смартфонов, участвующих в атаке.
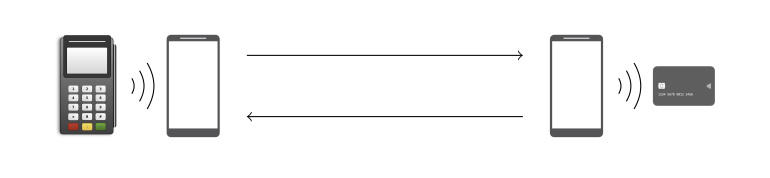
Один из телефонов выступает в роли POS-терминала, он должен находиться рядом с украденной картой.
Принцип атаки заключается в следующем: эмулятор POS-терминала запрашивает у карты оплату, модифицирует детали транзакции и затем отправлять уже изменённую информацию по Wi-Fi другому смартфону. Вводить PIN-код для совершения подобного платежа не потребуется.
Возможность атаки существует из-за уязвимости в стандарте EMV и бесконтактном протоколе Visa. Демонстрацию эксплуатации специалисты сняли на видео:






