














Специалисты «Эфшесть/F6» рассказали о новой кибершпионской группировке SiribClone, которая охотится за военнослужащими ВС РФ на приграничных территориях и в зоне проведения СВО. Цель у злоумышленников простая: добраться до телеграм-аккаунтов, переписки, контактов, геолокации и содержимого устройств.
По данным исследователей, следы активности группы нашли в феврале 2026 года, но первые атаки могли начаться ещё летом 2025-го.
Работают злоумышленники сразу по двум направлениям: заражают компьютеры и смартфоны шпионскими программами, а также крадут телеграм-сессии через фейковые страницы аутентификации.
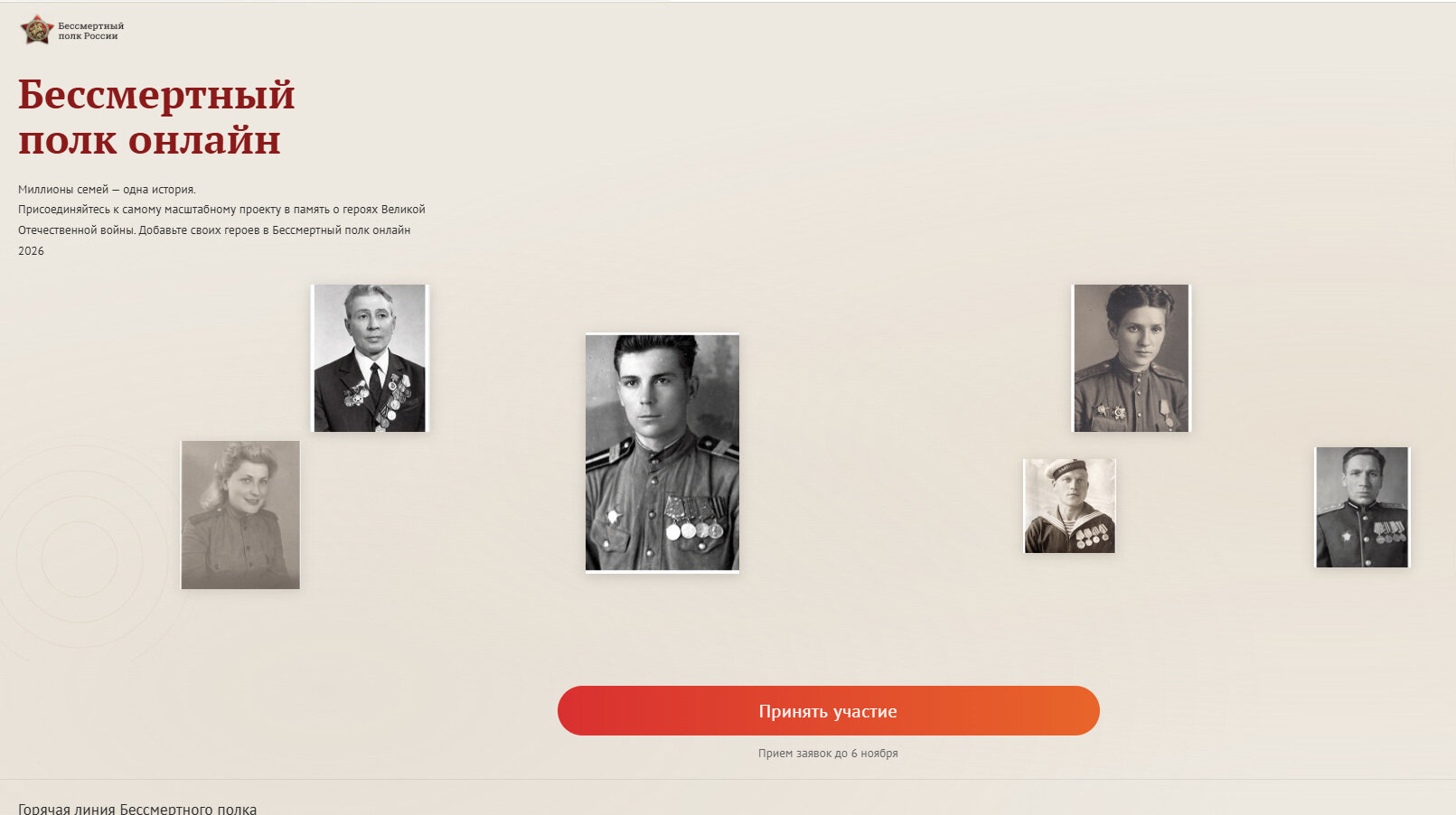
Для десктопов атакующие используют вредоносную программу SiribGrabber. Её распространяли под видом архивов с якобы ведомственными документами. Позже схему обновили: злоумышленники сделали фейковый сайт движения «Бессмертный полк», где при нажатии на кнопку «Принять участие» скачивался архив с вредоносной начинкой.
Со смартфонами схема ещё грязнее. Атакующие знакомятся с военными в мессенджерах и приложениях для знакомств под видом девушек. Дальше классика социальной инженерии: посмотри приложение, давай безопасно обмениваться фото, я программист, протестируй. В итоге жертве подсовывают APK-файл Safeintim, SafeintimZ или ZafeintimZ.
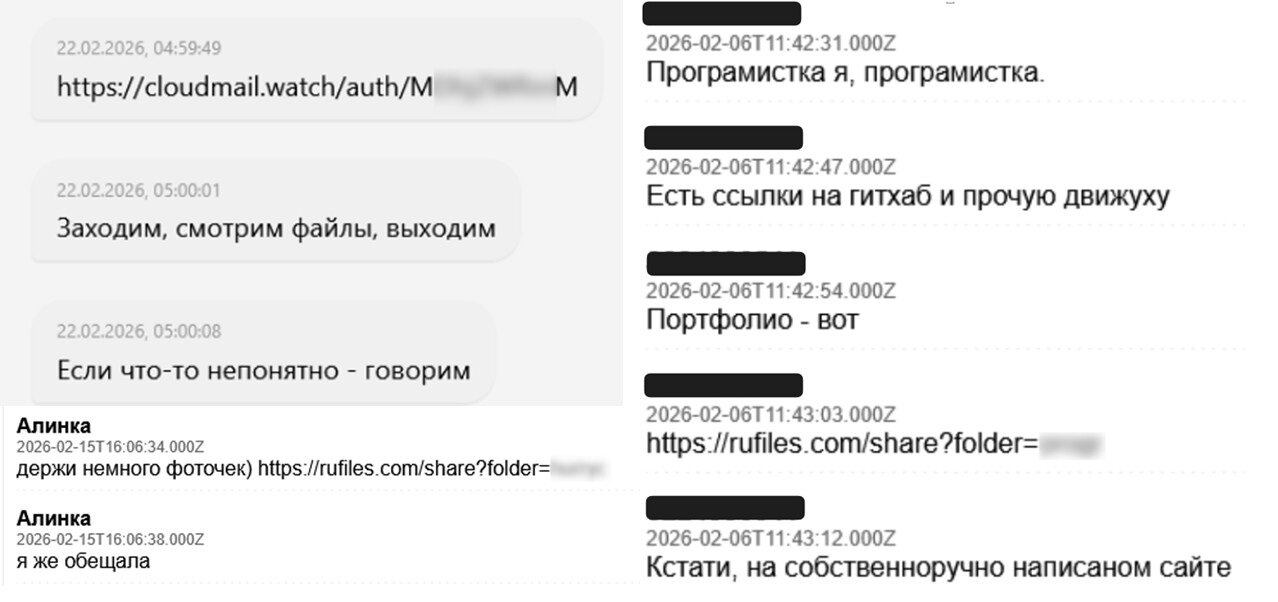
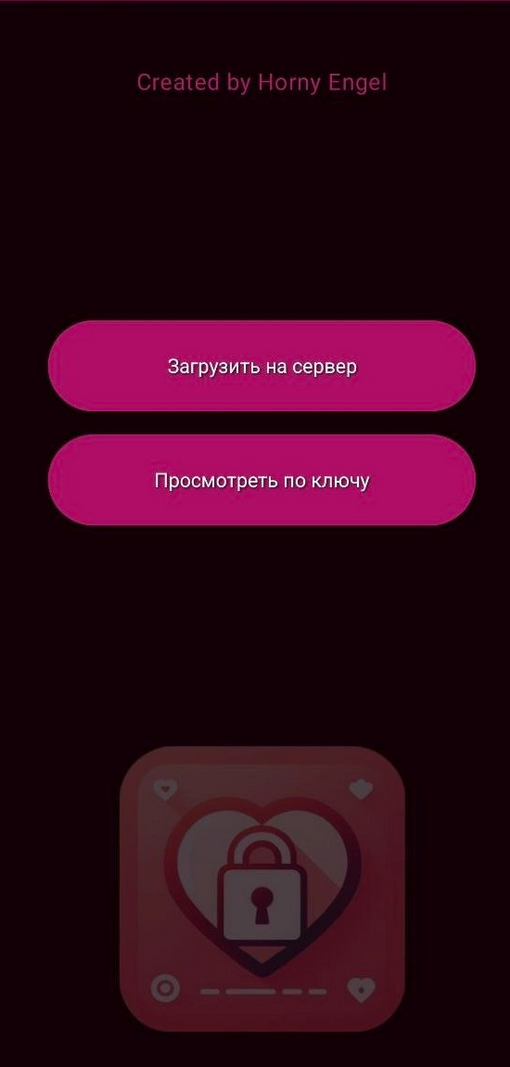
На деле это не приложение для обмена фото, а шпионская программа SafeLoveStealer. Она имитирует нормальную работу, но параллельно передаёт злоумышленникам данные устройства: фото, видео, документы, геопозицию, параметры сети и Wi-Fi. Также она может записывать звук с микрофона. То есть смартфон превращается в карманного осведомителя.
Есть и второй сценарий: атакующие изображают волонтёров и предлагают заполнить форму для получения гуманитарной помощи. Финал тот же — фишинг, вредоносная программа или попытка угнать Telegram.
«Эфшесть/F6» также обнаружила фейковые страницы входа в Telegram: под облачное хранилище, сообщества, результаты анализов и другие приманки. Пользователя просят ввести номер, код и 2FA-пароль. После этого переписка фактически уходит на сторону.
Судя по найденным заметкам злоумышленников, это не случайный криминал ради галочки, а именно военный шпионаж.



