








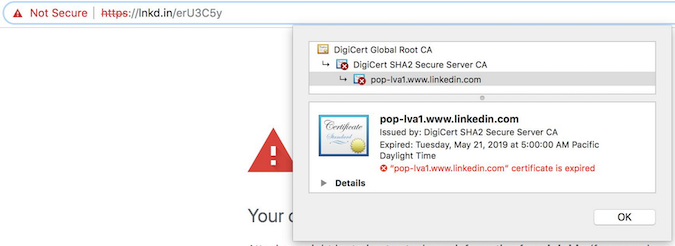
Социальная сеть LinkedIn, владельцем которой является корпорация Microsoft, в очередной раз поставила под угрозу данные своих пользователей и их конфиденциальность. Все дело в том, что платформа допустила использование просроченного TLS-сертификата.
На наличие проблемы обратили внимание пользователи LinkedIn. По словам юзера Майка Ортиза, при попытке зайти в систему LinkedIn (как на десктопе, так и на ноутбуке) выводилось предупреждение о небезопасном соединении.
Оказалось, что соцсеть банально забыла обновить сертификат TLS для своего сервиса коротких URL lnkd.in.
К счастью, компания не стала долго тянуть, заменив сертификат новым, срок действия которого истечет в мае 2021 года.
Напомним, что это уже второй такой случай в LinkedIn. Первый датируется ноябрем 2017 года — тогда компания забыла обновить сертификат для доменов, используемых для разных стран, вроде uk.linkedin.com или de.linkedin.com.






