















Исследователи HUMAN раскрыли крупную кампанию под названием Trapdoor, нацеленную на пользователей Android. Схема объединяла вредоносную рекламу, фейковые приложения и скрытую накрутку показов. В операции использовались 455 вредоносных Android-приложений и 183 C2-домена, контролируемых злоумышленниками.
Пользователь скачивал вроде бы безобидное приложение — например PDF-просмотрщик, чистильщик устройства или другую утилиту.
После запуска оно показывало фейковые уведомления об обновлении и подталкивало установить ещё одно приложение. А вот уже второй этап запускал скрытые WebView, открывал HTML5-домены злоумышленников и начинал запрашивать рекламу.
В пике, по данным исследователей, Trapdoor генерировал до 659 млн рекламных запросов в день. Приложения, связанные с кампанией, скачали более 24 млн раз. Основной объём трафика шёл из США, на них пришлось больше трёх четвертей активности.
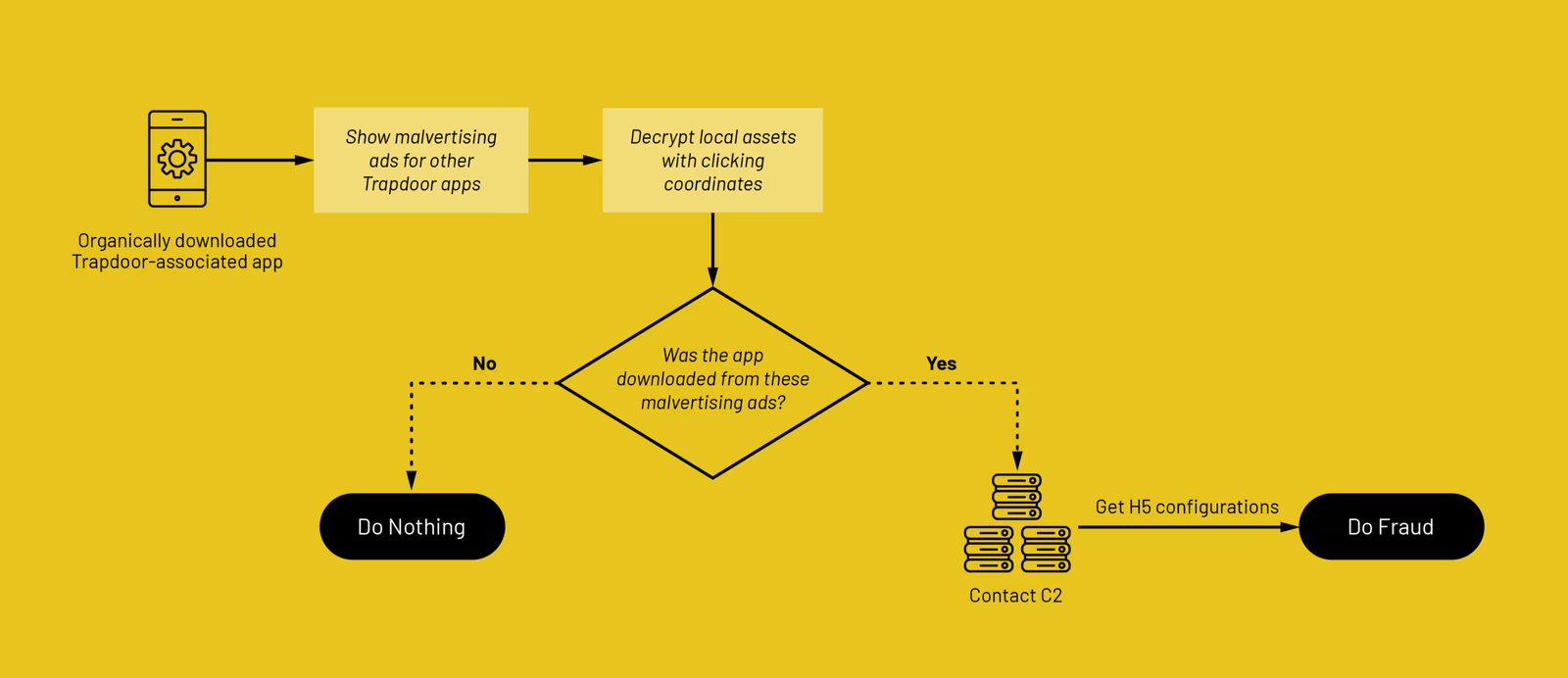
Главная хитрость в том, что мошенники использовали инструменты атрибуции установок — легитимные технологии, которые помогают маркетологам понимать, откуда пришёл пользователь.
Только здесь их применяли не для честной аналитики, а чтобы включать вредоносное поведение только у тех, кто пришёл через рекламные кампании самих злоумышленников. Если приложение скачать напрямую из Google Play или установить вручную, оно могло вести себя тихо и не палиться перед исследователями.
Trapdoor совмещал сразу несколько подходов: распространение через вредоносную рекламу, скрытую монетизацию через рекламный фрод и многоступенчатую доставку дополнительных приложений.
Второй этап занимался автоматизированным фродом, запускал невидимые WebView и обращался к подконтрольным доменам для получения рекламы. Короче, телефон пользователя превращался в маленький станок для печати рекламных денег.
Для маскировки операторы кампании использовали обфускацию, антианализ и имитацию легитимных SDK.



