







Неизвестные злоумышленники выложили в Сеть исходный код популярного приложения Snapchat. Несмотря на то, что компания оперативно приняла все возможные меры по удалению неправомерно выложенных данных, многие успели скопировать их.
Проблема, как оказалось, крылась в обновлении приложения, которое датируется маем. Именно оно позволило скачать часть исходного кода программы.
Об утечке впервые сообщили пользователи в Twitter, одним из которых был x0rz. В своем твите x0rz опубликовал ссылку на репозиторий GitHub, в котором якобы выложен исходный код Snapchat.
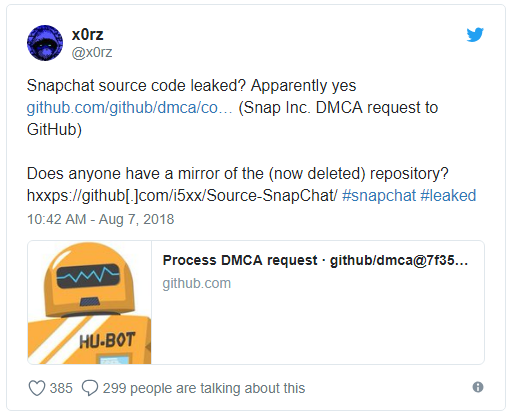
Как только компании стало известно, что исходный код их приложения стал доступен публично, она сразу направила официальные запросы с требованием удалить интеллектуальную собственность. Однако это мало на что могло повлиять, так как код успели скопировать уже многие пользователи.
Нетрудно догадаться, что теперь различные киберпреступники могут использовать утечку для поиска уязвимостей и багов, которые впоследствии можно использовать в реальных атаках на пользователей.






