Инициатива по поиску уязвимостей нулевого дня Zero Day Initiative (ZDI), основанная компанией Trend Micro, призывает исследователей искать 0-day бреши удаленного выполнения кода (RCE) в нескольких продуктах на стороне сервера. За некоторые из них ZDI обещает выплатить до 200 000 долларов.
Брайан Горенц, представитель ZDI, поясняет:
«Начиная с 1 августа мы будем предлагать специальную денежную премию за обнаружения отдельных недостатков безопасности. Предложение будет ограничено по времени».
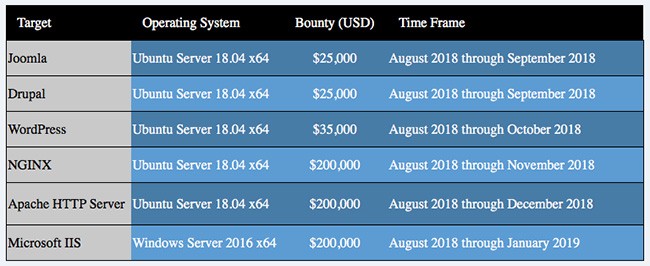
Исследователи смогут получить вознаграждения за бреши в следующих продуктах: Joomla, Drupal, WordPress, NGINX, Apache HTTP Server и Microsoft IIS.
Как только будет выплачен первое вознаграждение, продукт будет удален из списка. Зато в этом же списке появится новый продукт, обнаружение уязвимости в котором будет стоить своих денег. Первый исследователь, предоставивший рабочий эксплойт, позволяющий удаленно выполнить код, получит полную сумму вознаграждения.
Остальным тоже что-нибудь перепадет, так как их материалы все равно будут использованы ZDI, следовательно, за них заплатят определенную сумму в рамках другой программы по поиску уязвимостей.
Авторы инициативы подчеркивают, что 0-day эксплойт должен использовать уязвимость в самом продукте, а не в стороннем плагине или аддоне. Также обязательным условием является предоставление полностью рабочей версии эксплойта, а не только POC-кода.