






Жертвы последней крупной кибератаки, которая была проведена с помощью вируса-вымогателя Petya не смогут вернуть свои файлы. Об этом говорится в записи на официальном сайте «Лаборатории Касперского».
Эксперты лаборатории, проведя анализ той части вируса Petya, которая связана с шифрованием файлов, выяснили, что после заражения и шифрования жесткого диска «у создателей вируса уже нет возможности расшифровать его обратно».
Для расшифровки необходим уникальный идентификатор конкретной установки трояна, который не предусмотрен в этой версии вируса Petya. В других версиях шифровальщиков идентификатор содержал нужную для расшифровки информацию,
«Это означает, что создатели зловреда не могут получать информацию, которая требуется для расшифровки файлов. Иными словами, жертвы вымогателя не имеют возможности вернуть свои данные», — говорится в сообщении.
В «Лаборатории Касперского» эту версию вируса Petya назвали Expetr (aka NotPetya).
Кибератака вируса, который изначально был идентифицирован как Petya.A, произошла 27 июня. Предполагалось, что вирус блокировал компьютерные системы компаний, требуя за разблокировку данных сумму в биткоинах, эквивалентную $300.
Как стало известно 29 апреля, создатели вируса заработали на нем всего четыре биткоина или около $10 тыс. В «Лаборатории Касперского» опосредованно заявляли, что «служба e-mail, услугами которой пользовались злоумышленники, заблокировала почтовые адреса, на которые должны приходить данные об уплате выкупа».
Наибольшее число жертв от кибератаки в России и на Украине. В Киеве пострадали компьютерная система украинского правительства, аэропорт Борисполь, «Укрпочта», «Укртелеком», Министерство инфраструктуры, ряд банковских структур. В России под атаку попали компьютерные системы «Роснефти» и «Башнефти», а также Банка Хоум Кредит.
Впоследствии появлялись сообщения о распространении вируса в Италии, Израиле, Сербии, Румынии, США, Литве, Венгрии, а также Польше, Аргентине, Чехии, Германии и России.
В «Лаборатории Касперского» ранее заявляли, что вирус относится к новому семейству вредоносного программного обеспечения, не упоминая о возможной потере данных. Тогда в лаборатории говорили, что планируют создать специальный инструмент-дешифратор, с помощью которого можно будет расшифровывать данные.
Стоит сказать, что с самого начала атак некоторые исследователи предполагали, что Petya далеко не так прост, как кажется. В частности многим казалось странным, что операторы шифровальщика предусмотрели всего один биткоин-кошелк для перечисления выкупов, да еще и жестко прописали его в код вредоноса. Не менее странным выглядело и создание единственного почтового адреса на Posteo, потому как его оперативную блокировку можно без труда предвидеть. Словом, новая версия Petya, взявшая на вооружение эксплоиты АНБ ETERNALBLUE и ETERNALROMANCE, мало походит на классическую «машину для генерации денег», каковой обычно и являются вымогатели.
«Несмотря на значительное количество одинакового кода, оригинальный Petya был криминальным предприятием для заработка денег. Эта [новая версия] определенно создана не с целью заработать денег. Она создана, чтобы быстро распространяться и причинять ущерб, и действует под правдоподобным прикрытием, как вымогатель», — пишет известный ИБ-специалист The Grugq.
Теперь теории экспертов начинают подтверждаться. Специалисты «Лаборатории Касперского» и исследователь Comae Technologies Мэтью Сюиш (Matt Suiche) пришли к выводу, что Petya вообще некорректно называть шифровальщиком. Дело в том, что вредонос, по сути, создан для уничтожения информации, — восстановить пострадавшие данные мало реально, и это не ошибка, а замысел авторов малвари. Поэтому Petya скорее следует называть вайпером (wiper),
Исследователи «Лаборатории Касперского» объясняют, что каждой зараженной машине Petya присваивает собственный ID, однако данный ID не передается на управляющий сервер (Petya вообще не имеет таковых) и не содержит в себе никакой ценной информации, которая позже помогла бы злоумышленникам «опознать» жертву и предоставить ей ключ для расшифровки файлов.
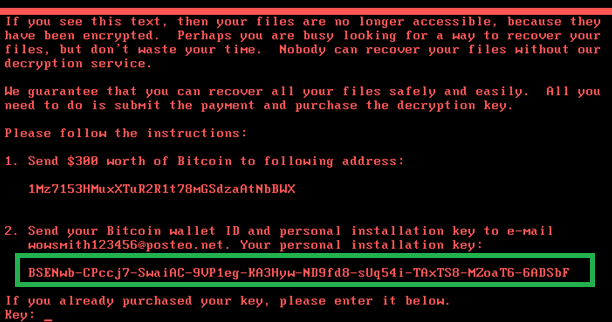
Как новая версия Petya генерирует ID, показано на иллюстрациях ниже. Малварь использует для этого функцию CryptGenRandom, то есть генерирует случайную последовательность ничего не значащих символов. Такой ID не несет в себе ровным счетом никакой информации, создается лишь для отвода глаз и точно не поможет расшифровать файлы. Таким образом, платить выкуп бесполезно не только из-за того, что Posteo заблокировал почтовый ящик преступников.

В своем отчете Мэтью Сюиш сравнивает Petya с другим известным вайпером, Shamoon. Исследователь сообщает, что зашифрованные Petya диски практически невозможно восстановить. Сравнив Petya образца 2016 года с новой версией, эксперт не мог не заметить существенную разницу: новая версия намеренно уничтожает первые 25 секторов на диске. Первый сектор диска шифруется с помощью XORс 0x07, после чего сохраняется в другом секторе и заменяется кастомным загрузчиком. Но все 24 следующие за ним сектора перезаписываются намеренно и нигде не сохраняются.
Petya 2017 слева и Petya 2016 справа
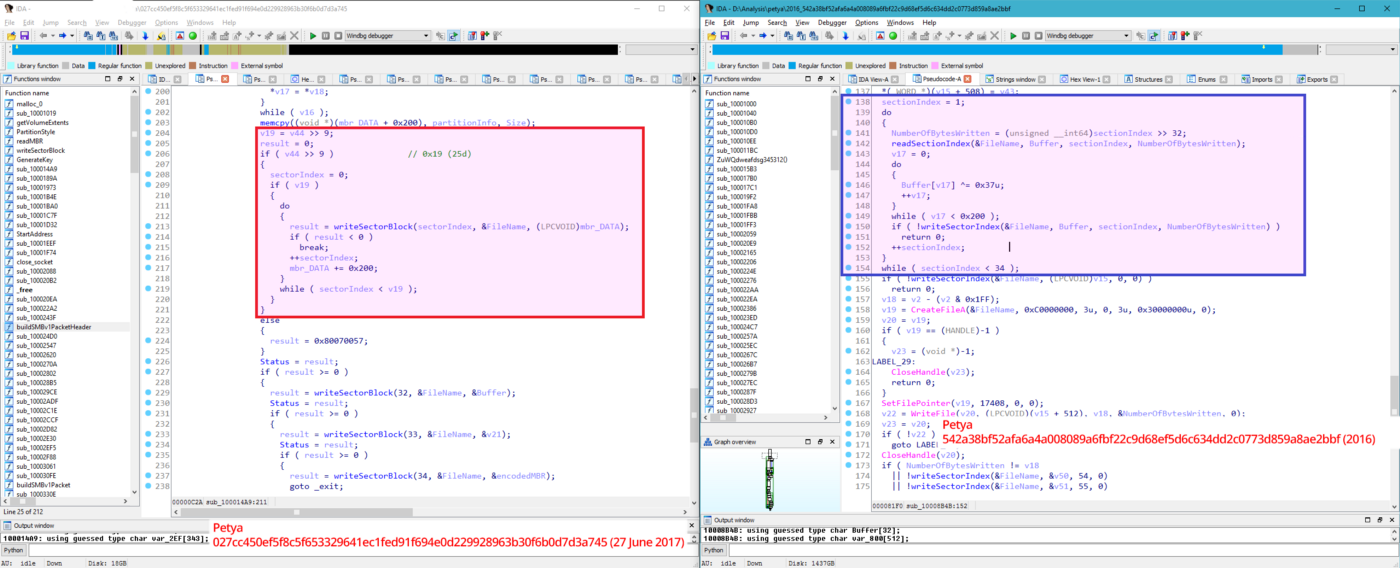
Оригинальный Petya тоже производил похожие операции, однако он действительно мог обратить все сделанные изменения, тогда как новый Petya повреждает данные умышленно и гораздо серьезнее.






