














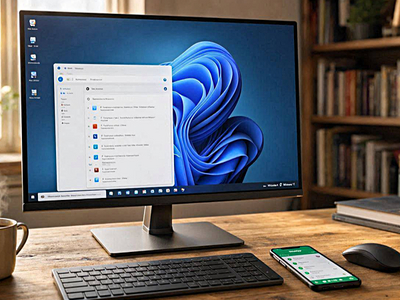
Microsoft начала массово развёртывать функцию «Возобновить» для WhatsApp (принадлежит корпорации Meta, признанной экстремистской и запрещённой в России) в Windows 11. Она позволяет открыть на компьютере чат, которым пользователь только что занимался на Android-смартфоне. Звучит как аналог Handoff от Apple. Работает тоже почти красиво, пока не запускается сам WhatsApp.
После получения сообщения на панели задач появляется логотип мессенджера с маленьким значком телефона.
![]()
Он отделён от остальных приложений вертикальной чертой. При наведении Windows предлагает продолжить на этом компьютере, а после нажатия открывает нужный чат.
Проблема в том, что клиент WhatsApp для Windows может загружаться дольше, чем пользователь достанет телефон и ответит самостоятельно. Приложение работает как оболочка WebView2 с веб-версией мессенджера внутри.
После синхронизации чатов оно способно занимать около 1,2 Гбайт оперативной памяти, тормозить при прокрутке и не спешить с отправкой сообщений.
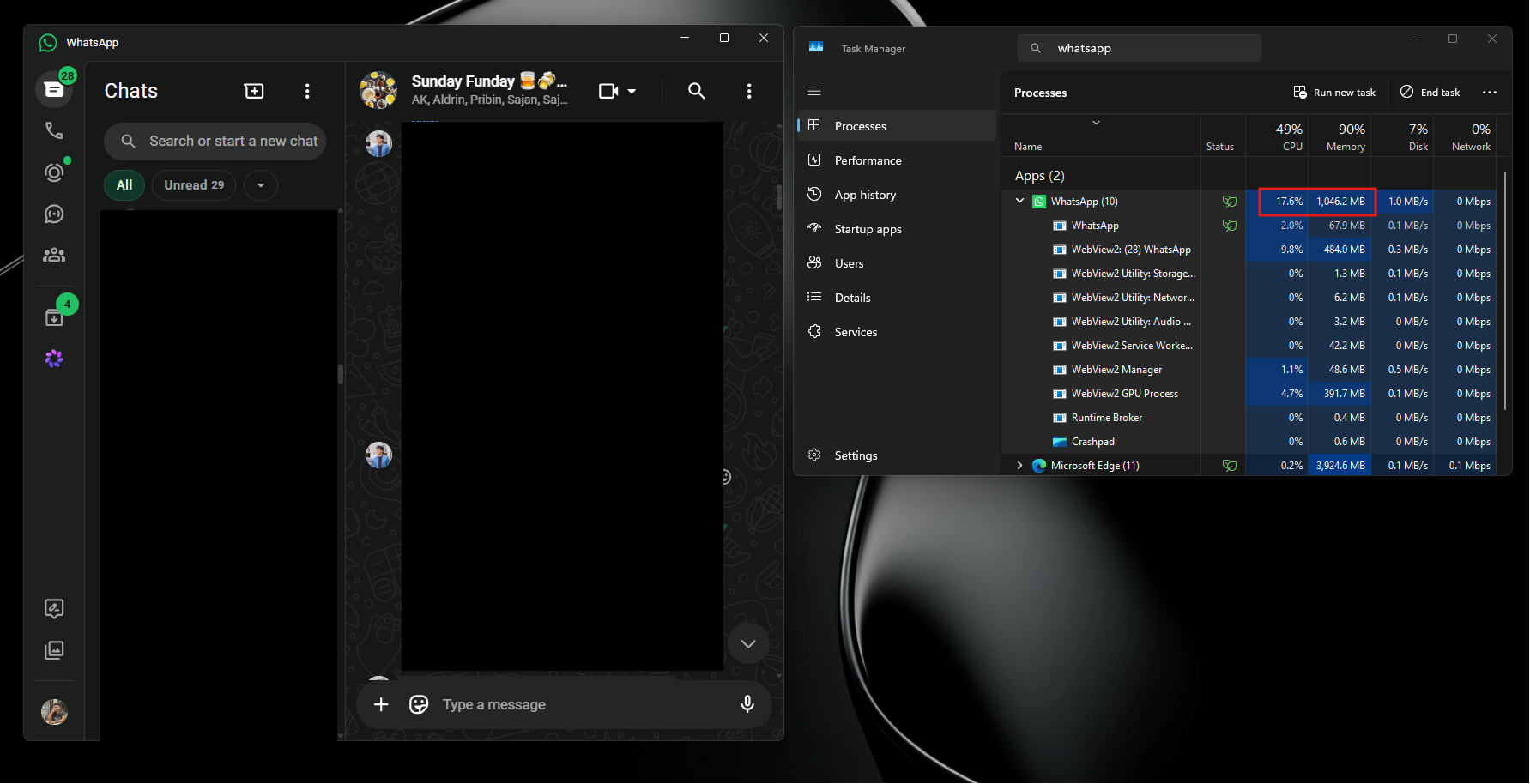
Получается странный аттракцион: Microsoft два года строила удобный мост между Android и Windows, а на другом берегу поставили медленный веб-клиент.
Отключить перенос WhatsApp можно в разделе «Параметры» → «Приложения» → «Возобновить». Уведомления мессенджера после этого продолжат работать.
Сама идея у Microsoft отличная. Но быстрый ярлык для запуска медленного приложения не делает приложение быстрее. Он просто помогает добраться до тормозов раньше.



