Группа, в которую вошли исследователи из ряда известных университетов, а также представители Mozilla, Cloudflare и Google, провела анализ распространения методов локального перехвата HTTPS-трафика и влияния такого перехвата на сетевую безопасность.
Результаты превзошли ожидания исследователей, оказалось, что 4-11% HTTPS-трафика перехватывается и анализируется сторонним ПО на стороне клиента (антивирусное ПО, межсетевые экраны), при этом в большинстве случаев подобный перехват приводит к уменьшению уровня защиты соединения.
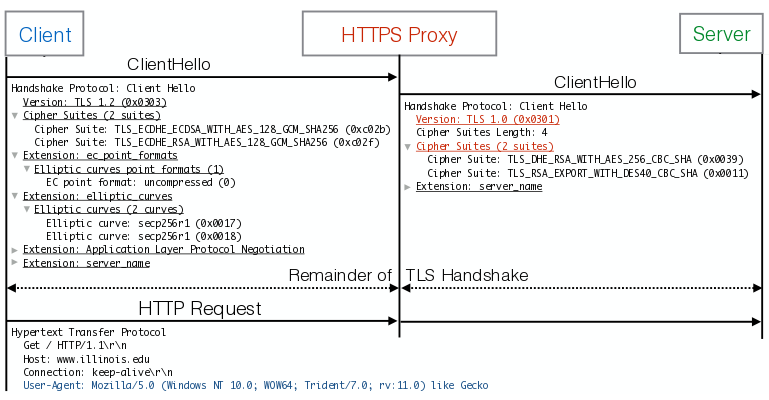
Под локальным перехватом подразумеваются случаи анализа HTTPS-трафика с использованием программного обеспечения, установленного на системе пользователя (например, антивирусное ПО), или применением корпоративных шлюзов инспектирования трафика, работающих в виде прокси. Подобные системы перехватывают обращение клиента, затем от своего лица и с собственным сертификатом транслируют HTTPS-запрос на сервер, получают ответ и отдают его клиенту в рамках отдельного HTTPS-соединения, установленного с использованием SSL-сертификата перехватывающей системы. Для сохранения индикатора защищённого соединения в браузере на машины клиента устанавливается дополнительный корневой сертификат, позволяющий скрыть работу применяемой системы инспектирования трафика, пишет
Исследователи разработали ряд эвристических методов, позволивших на стороне сервера выявить факты перехвата HTTPS и определить какие именно системы использовались для перехвата. На основании заголовка User Agent определялся браузер, а затем сравнивались специфичные для браузера и фактические особенности устанавливаемого TLS-соединений. Более того, сопоставив такие характеристики TLS-соединения, как параметры по умолчанию, поддерживаемые расширения, заявленный набор шифров, порядок определения шифров и методы сжатия, удалось достаточно точно определить конкретный продукт, применяемый для перехвата трафика.
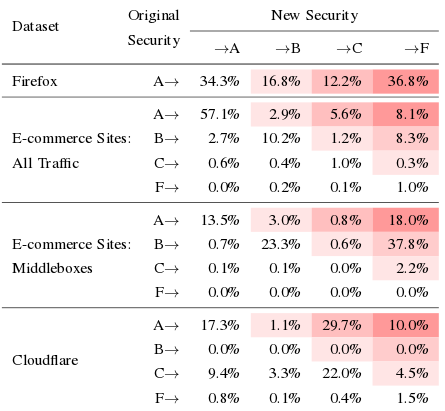
Серверные компоненты для определения подмены HTTPS-соединения были установлены на серверы распространения обновлений для Firefox, в сеть доставки контента Cloudflare и на некоторые популярные интернет-магазины. В итоге, на серверах обновления Firefox выявлено 4% перехваченных запросов, в интернет-магазинах - 6.2%, а в CDN-сети Cloudflare - 10.9%. В 62% случаев использование корпоративных систем инспектирования снижало безопасность соединения из-за применения менее надёжных алгоритмов шифрования, а в 58% случаев соединения были подвержены известным уязвимостям. В 10-40% случаев системы перехвата анонсировали при установке соединения с сервером поддержку небезопасных шифров, подверженных MITM-атакам.
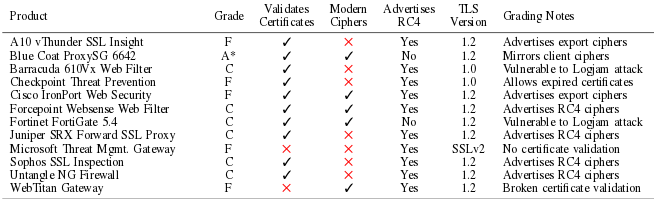
Из рассмотренных 12 шлюзов инспектирования только 5 предлагали актуальный набор шифров, 2 вообще не осуществляли верификацию сертификатов (Microsoft Threat Mgmt и WebTitan Gateway).
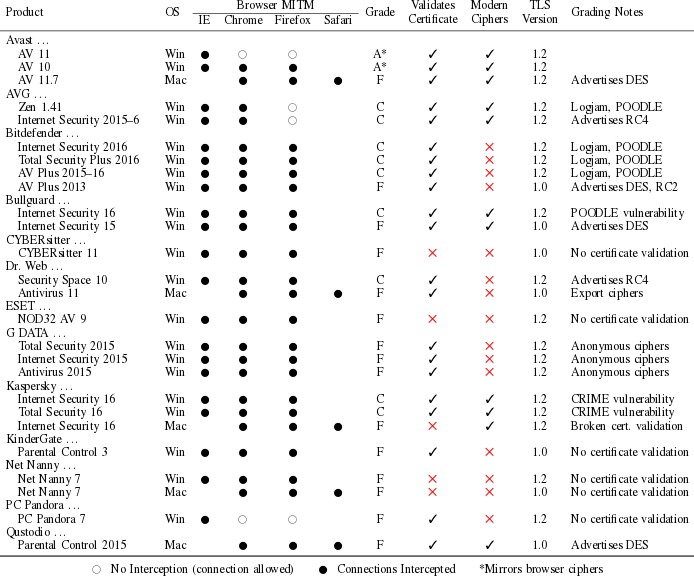
24 из 26 протестированных систем перехвата, работающих на компьютере клиента (как правило антивирусы), снижали общий уровень безопасности HTTPS-соединения. Актуальные наборы шифров предоставлялись в 11 из 26 продуктов. 5 систем не осуществляли верификацию сертификатов (Kaspersky Internet Security 16 Mac, NOD32 AV 9, CYBERsitter, Net Nanny 7 Win, Net Nanny 7 Mac). Продукты Kaspersky Internet Security и Total Security подвержены атаке CRIME. Продукты AVG, Bitdefender и Bullguard подвержены атакам Logjam и POODLE. Продукт Dr.Web Antivirus 11 позволяет откатиться на ненадёжные экспортные шифры (атака FREAK).
Интересно, что поддерживаемая современными браузерами возможность привязки сертификата к сайту (public key pinning) не работает в случае применения систем локального перехвата трафика. Chrome, Firefox и Safari выполняют данную проверку только если цепочка проверки ключей связана с сертификатом удостоверяющего центра. Проверка не выполняется, если цепочка верификации завершается локальным корневым сертификатом, установленным администратором.
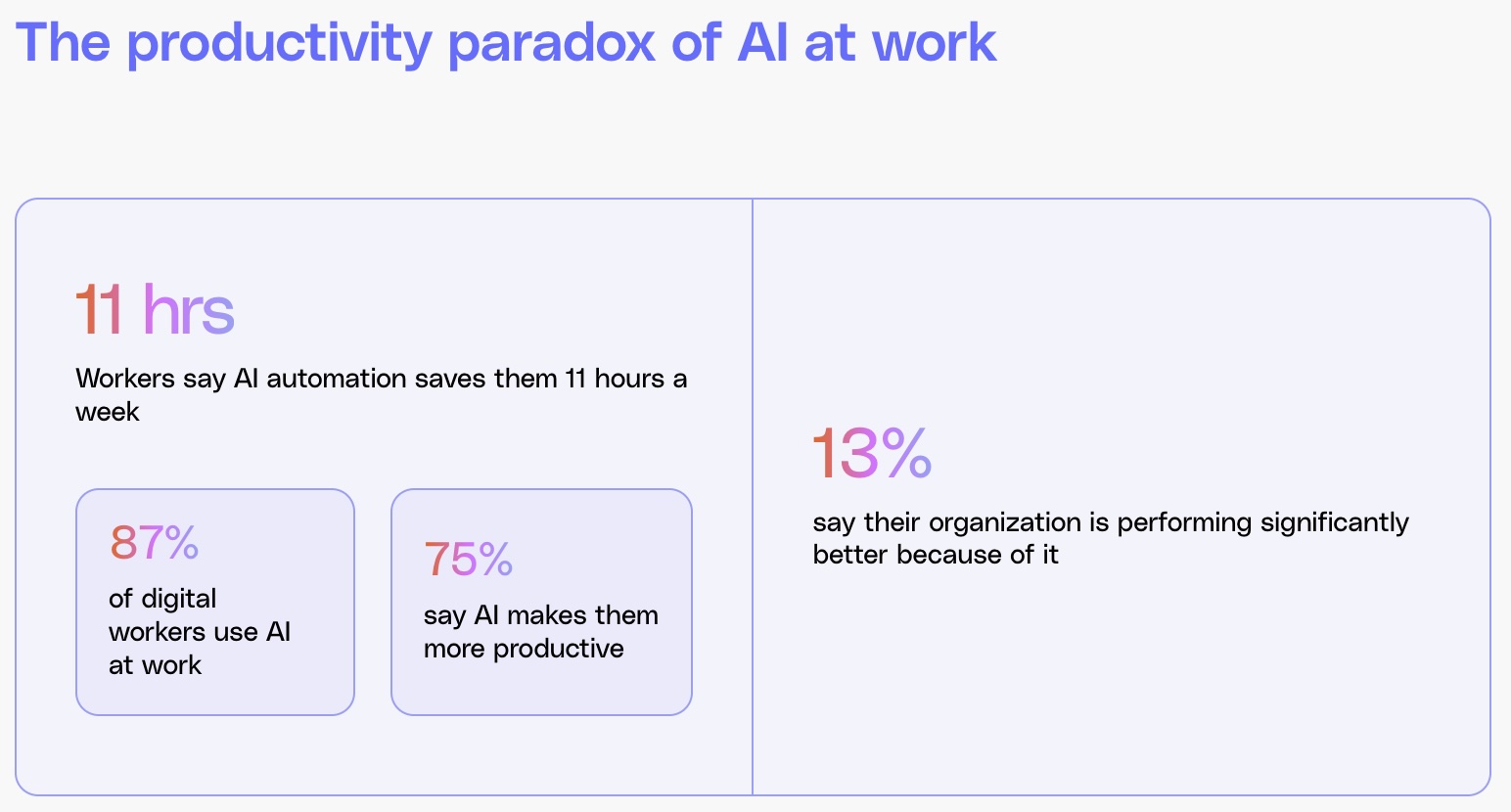
Искусственный интеллект попал в неудобную статистику. Новое исследование Work AI Institute показало, что сотрудники действительно экономят время благодаря ИИ — в среднем около 11 часов в неделю. Но есть нюанс: более шести часов из этой экономии приходится тратить на проверку, исправление и контроль работы самого ИИ.
Исследование охватило 6000 офисных сотрудников из США, Великобритании и Австралии.
Опрос показал, что 75% работников заметили рост личной продуктивности после внедрения ИИ-инструментов. Однако только 13% компаний сообщили о заметном росте бизнеса благодаря этим технологиям.
Получается любопытный парадокс. Формально сотрудники работают быстрее, но бизнес почему-то не получает сопоставимой выгоды.
По словам профессора Калифорнийского университета Пола Леонарди, многие недооценивают объём скрытой работы, которая появляется вместе с ИИ. Нужно собирать данные, подготавливать контекст, перепроверять ответы чат-ботов, искать ошибки и дорабатывать результаты вручную.
Фактически современные сотрудники всё чаще выступают не исполнителями, а менеджерами собственных цифровых помощников.
Согласно исследованию, 37% времени взаимодействия с ИИ уходит непосредственно на работу с ботами, а ещё 36% — на применение полученных результатов в реальных задачах. Более того, 41% опрошенных признались, что не могут объяснить, каким образом ИИ пришёл к своим выводам.
Авторы приводят показательный пример. Молодой разработчик перед уходом домой интегрировал в проект тысячи строк кода, сгенерированного ИИ. После этого система перестала работать, а разбираться в причинах пришлось старшему инженеру. Сам автор изменений не смог объяснить, что именно сделал искусственный интеллект.
Свидетельство о регистрации СМИ ЭЛ № ФС 77 - 68398, выдано федеральной службой по надзору в сфере связи, информационных технологий и массовых коммуникаций (Роскомнадзор) 27.01.2017 Разрешается частичное использование материалов на других сайтах при наличии ссылки на источник. Использование материалов сайта с полной копией оригинала допускается только с письменного разрешения администрации.